Select is fundamentally broken
I/O multiplexing part #2
In a previous blog post we discussed
a brief history of the select(2) syscall. The
article concludes that some I/O multiplexing was necessary to
do console emulation, games and non-trivial TCP/IP applications.
The BSD designers chose the select multiplexing model and other
Unixes followed. But is select the only multiplexing model?
A good explanation can be found in the old revision of "The Design and Implementation of the FreeBSD Operating System" book. Google books has it, here's a snippet:
There are four possible alternatives that avoid the blocking problem:
- Set all the descriptors in nonblocking mode. [...]
- Enable all descriptors of interest to [send] signal when I/O can be done. [...]
- Have the system provide a method for asking which descriptors are capable of performing the I/O [...]
- Have the process register with the [operating] system all the events including I/O on descriptors that it is interested in tracking.
Option 1) is naive. The idea is to do busy-polling on non-blocking descriptors. It requires using 100% CPU. It's not very practical.
Option 2) is the good old
SIGIO async I/O
model. Linux implements it with
fcntl(F_SETSIG). With fcntl
set up, a signal will notify your process when readability /
writeability on descriptor changes. Sadly F_SETSIG model in its
current implementation is almost totally useless1.
Option 3) is a model exposed by the select(). It's simple, well
defined and easy to understand. This is the model shared by poll and
epoll syscalls.
Option 4) is the interesting one. The idea is to shift some state to
the kernel and let it know what precisely we want to do on the file
descriptor. This is model exposed by kqueue and Windows IOCP.
Each of these four multiplexing models have their weaknesses, but I'd
like to focus specifically on the third option: select.
Heavyweight
Select() was
first implemented 33 years ago,
and for that age it holds remarkably well. Unfortunately it's broken
by design.
It's not only select() syscall that is broken. All technologies
which inherit its semantics are broken too! This includes select,
poll, and to lesser extent epoll.
The usual argument against select is that the API mandates a linear
traversal of file descriptors. This is true, but it's not the biggest
issue in my opinion. The select semantics prevent the kernel from
doing any optimizations. It is impossible to create fast kernel-side
select implementation.
Whenever your process enters the select(), the kernel must iterate
through the passed file descriptors, check their state and register
callbacks. Then when an event on any of the fd's happens, the kernel
must iterate again to deregister the callbacks. Basically on the
kernel side entering and exiting select() is a heavyweight
operation, requiring touching many pointers, thrashing processor
cache, and there is no way around it.
Epoll() is Linux's solution. With it the developer can avoid
constantly registering and de-registering file descriptors. This is
done by explicitly managing the registrations with the epoll_ctl
syscall.
But epoll doesn't solve all the problems.
Thundering herd problem
Imagine a socket descriptor shared across multiple operating system processes. When an event happens all of the processes must be woken up. This might sound like a bogus complaint - why would you share a socket descriptor? - but it does happen in practice.
Let's say you run an HTTP server, serving a large number of short
lived connections. You want to accept() as many connections per
second as possible. Doing accept() in only one process will surely
be CPU-bound. How to fix it?
A naive answer is: let's share the file descriptor and allow multiple
processes to call accept() at the same time! Unfortunately doing
so will actually degrade the performance.
To illustrate the problem I wrote two pieces of code.
First, there is
server.c
program. It binds to TCP port 1025 and before blocking on select it
forks a number of times. Pseudo code:
sd = socket.socket() sd.bind('127.0.0.1:1025') sd.listen() for i in range(N): if os.fork() == 0: break select([sd])
To run 1024 forks all hanging in select on one bound socket:
$ ./server 1024 forks = 1024, dupes per fork = 1, total = 1024 [+] started
The second program
client.c
is trivial. It's connecting to the TCP port measuring the time. To
better illustrate the issue it does a nonblocking connect(2)
call. In theory this should always be blazing fast.
There is a caveat though. Since the connection is going over loopback
to localhost, the packets are going to be processed in-line, during
the kernel handling of the connect syscall.
Measuring the duration of a nonblocking connect in practice shows
the kernel dispatch time. We will measure how long it takes for the
kernel to:
- create a new connection over loopback,
- find the relevant listen socket descriptor on the receiving side,
- put the new connection into an accept queue
- and notify the processes waiting for that listen socket.
The cost of the last step is proportional to the number of processes
waiting on that socket. Here is a chart showing the duration of the
connect syscall rising linearly with the number of processes waiting
in select on the listen socket:
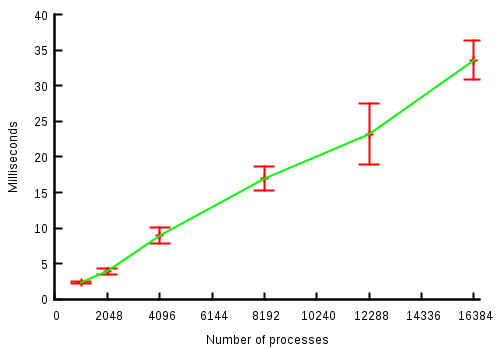
Calling non-blocking connect() to a listen socket which is shared
across 16k processes takes 35 milliseconds on my machine.
These results are expected. The kernel needs to do linearly more work
for each process it needs to wake up, for each of the file descriptors
the process is blocking on in select(). This is also true for
epoll().
Extreme experiment
Let's take this experiment to an extreme. Let's see what happens when
we have not one listen socket waiting in the select loop, but a
thousand. To make kernel job harder we will copy the TCP port 1025
bound socket a thousand times with dup(). Pseudo code:
sd = socket.socket() sd.bind('127.0.0.1:1025') sd.listen() list_of_duplicated_sd = [dup(sd) for i in xrange(1019)] for i in range(N): if os.fork() == 0: break select([sd] + list_of_duplicated_sd)
This is implemented in the server.c as well:
marek:~$ ./server 1024 1019 forks = 1024, dupes per fork = 1019, total = 1043456 [+] started
The chart will show a linear cost, but with a much greater constant factor:
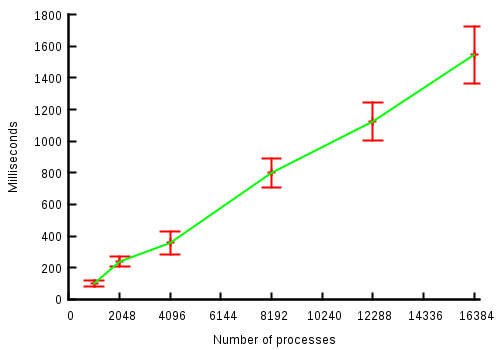
The chart confirms a very large cost of such setup. With 16k running
processes, each with the listen socket dup'ed 1019 times (16M file
descriptors total) it takes the kernel an amazing 1.5 seconds to perform
the localhost non-blocking connect().
This is how it looks in console:
marek:~$ time nc localhost 1025 -q0 real 0m1.523s marek:~$ strace -T nc localhost 1025 -q0 ... connect(3, {sa_family=AF_INET, sin_port=htons(1025), sin_addr=inet_addr("127.0.0.1")}, 16) = -1 EINPROGRESS (Operation now in progress) <1.390385> ...
This setup overwhelms the machine. Our single event rapidly moves thousands of our Linux processes from "sleep" process state to "runnable" resulting in interesting load average numbers:
marek:~$ uptime
load average: 1388.77, 1028.89, 523.62
Epoll exclusive to the rescue
This is a classic thundering herd problem. It's helped with a new
EPOLLEXCLUSIVE epoll_ctl flag. It was added very recently to
kernel 4.5. Man page
says:
EPOLLEXCLUSIVE (since Linux 4.5) Sets an exclusive wakeup mode for the epoll file descriptor that is being attached to the target file descriptor, fd. When a wakeup event occurs and multiple epoll file descriptors are attached to the same target file using EPOLLEXCLUSIVE, one or more of the epoll file descriptors will receive an event with epoll_wait(2).
Here's the relevant kernel patch:
If I understand the code right, it is intended to improve the average
case. The patch doesn't fundamentally solve the problem of the kernel
dispatch time being a costly O(N) on the number of processes /
descriptors.
Recap
I explained two issues with the select() multiplexing model.
It is heavyweight. It requires constantly registering and unregistering processes from the file descriptors, potentially thousands of descriptors, thousands times per second.
Another issue is scalability of sharing socket between processes. In the traditional model the kernel must wake up all the processes hanging on a socket, even if there is only a single event to deliver. This results in a thundering herd problem and plenty of wasteful process wakeups.
Linux solves first issue with an epoll syscall and second with
EPOLLEXCLUSIVE band aid.
I think the real solution is to fundamentally rethink the socket
multiplexing. Instead of putting band aids on "Option 3)" from Kirk
McKusick's book, we should focus on "Option 4)" - the kqueue and
IOCP interfaces.
But that's a subject for another article.
Update:
A couple of further technical links:
- poll() on OS X is broken
- poll vs select by Daniel Stenberg
- poll behaviour on EOF by Richard Kettlewell
- EPOLLEXCLUSIVE corner cases
-
There are too many problems with
F_SETSIGimplementation, don't get me started. Let's just say that when you catch theSIGIOsignal, you aren't given a reliable information showing the file descriptor on which the event happened. ↩
or leave a comment here.