Strange Loop - IP Spoofing
I recently gave a talk at the Strange Loop conference in St Louis.
The recording and slides are available, but for easier consumption here's a transcript.

Good morning! This is the DDoS talk. It's always hard to speak about DDoS. Many people mean very different things by it. Some say "DDoS" when their Ruby app can't handle more than five concurrent users.
But slow Ruby servers are not the subject of this talk. Here, I'm going to talk about one specific kind of DDoS attacks - the really big ones, the ones that make it to the news. Perhaps you've read headlines like "a DDoS attack that threatens the internet". This presentation will explain all the technical details behind attacks like that.
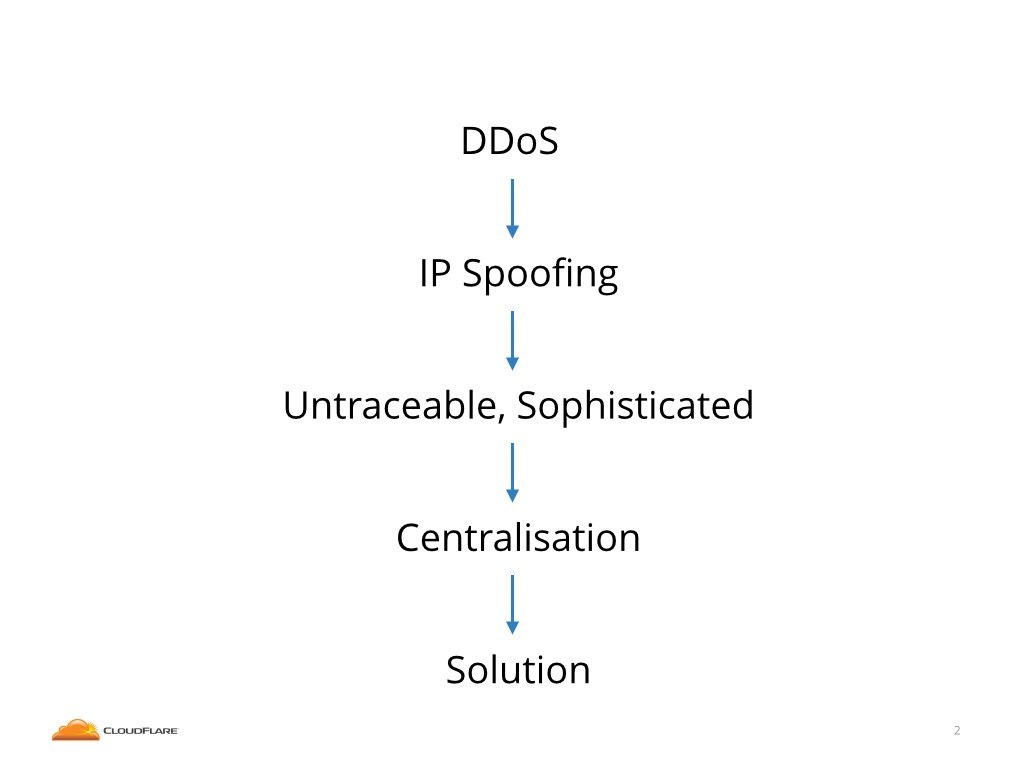
Before we start let me give you a roadmap of this talk. First I'll explain the Distributed Denial Of Service attacks, or DDoS, attacks. These are the attacks where somebody uses many machines to deny the access to some internet service. Basically try to take someone off the internet.
Then I'll make a case that IP spoofing, which is faking the IP addresses, allows the most serious attacks. I'll explain why it's impossible to trace the offender. I'll show examples of sophisticated attacks are possible due to IP spoofing.
I'll conclude that the only way to defend from such attacks is to invest in expensive infrastructure. This is one of the forces that leads to the centralization of the internet.
Finally I'll show how to untangle this mess. I'll explain what can be done to fix the problem.
Ok, let's start up, let me explain why DDoS attacks are a problem.
But why should I know anything about that?
Allow me introduce myself. My name is Marek and I'm an engineer at a performance and security company called Cloudflare.
At Cloudflare we operate a service - a globally distributed reverse proxy.
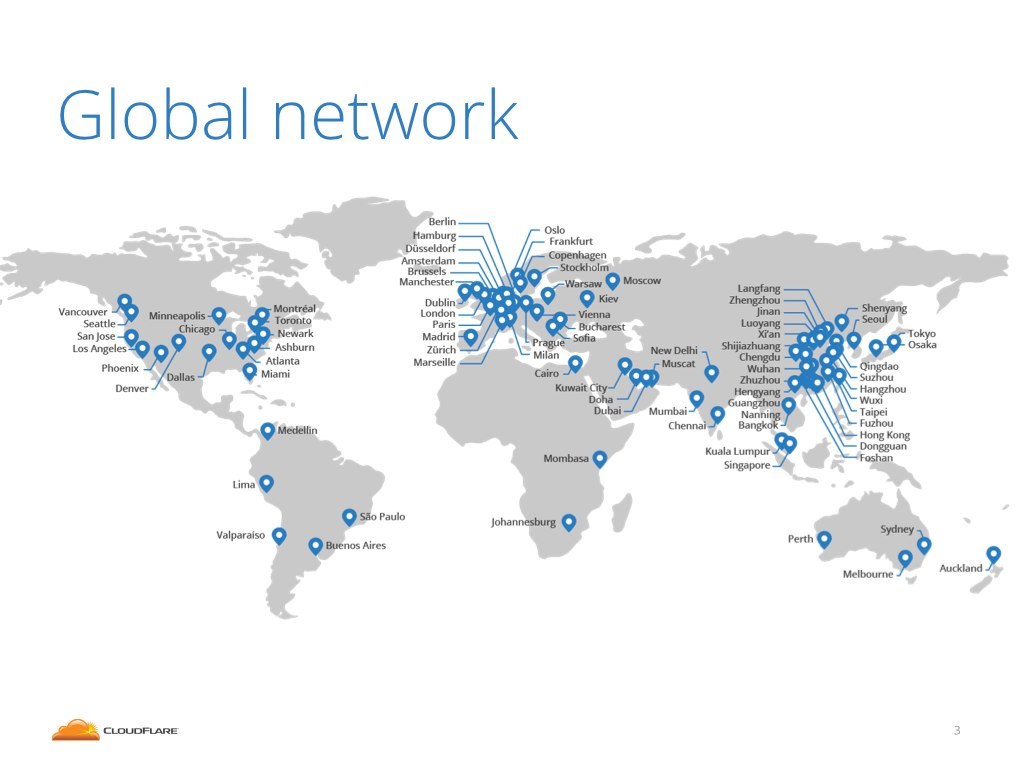
We run servers all around the world. At last count we were present in 86 locations 1. We see a big chunk of traffic crossing the internet.
We have plenty of customers from many different countries and from all industries: from dating portals through social media sites to government agencies. But most importantly we are content neutral.
We try not to discriminate websites based on the content they provide.
Operating a content neutral service in today's internet is a tough job. Some people dislike some websites, and they want to stop them from being available on the internet. The easiest way to do so is to launch a DDoS attack.
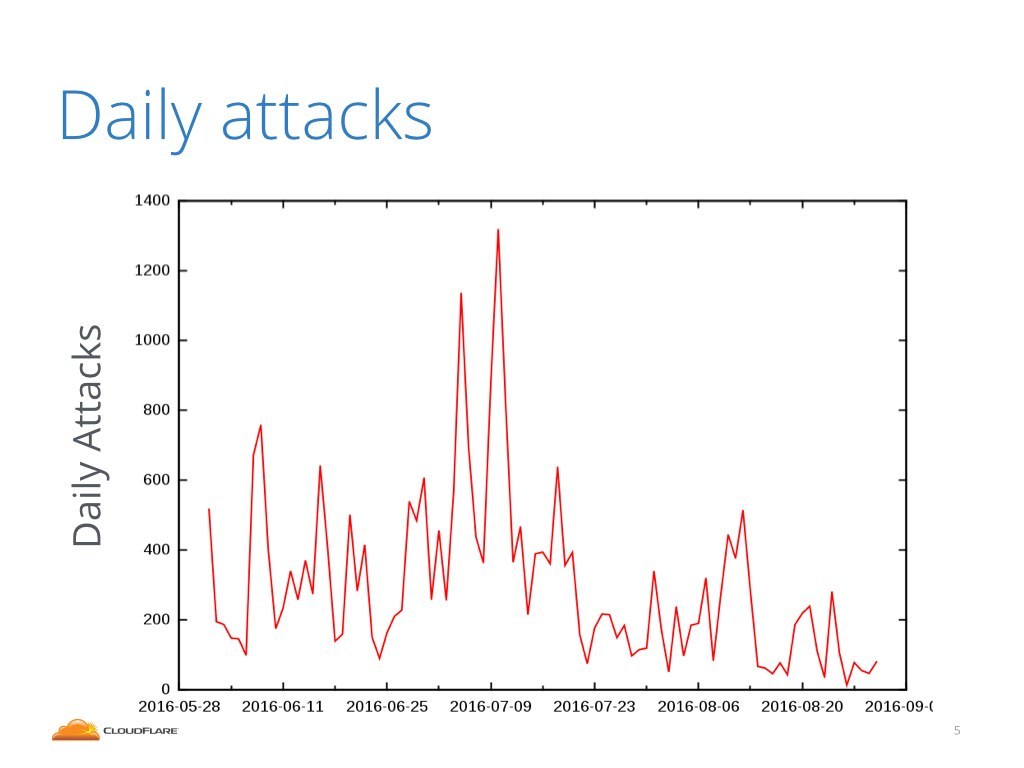
Being a middle man Cloudflare sees many of these attacks. This is not scaremongering, the attacks do happen all the time.
Here's a chart of last 90 days of the attacks we saw. The X axis shows time - in days, the Y axis shows number of DDoS events we saw on that day. On slower days we saw between 50 and 200 DDoS events, on busier days we saw up to 1200 separate incidents.

But fighting these attacks is not something we do because it's fun. In order to survive on the internet we had to adapt and learn how to withstand them.
Believe me, nobody enjoys handling attacks. This is a huge distraction and we'd much rather spend time on doing something constructive. It would be awesome if it was possible to fix the internet and solve the attacks one day.
As a part of a wider effort to help others with DDoS, we try to share our DDoS mitigation experience. We are trying to make public as much of the details as we can.

Over the years we published many stories of record breaking attacks. In this presentation I'll focus on three specific big attacks: Spamhaus DNS amplifications from 2013, the direct attacks we dubbed "Winter of attacks" from March this year and a new type of attacks we noticed only recently which I call a "Direct subnet" attacks.
Don't worry if these names don't mean much to you, I'll explain the details later in this talk.
It's very important to understand that these record breaking attacks are not coming out of the void. All of them had two things in common.

(Almost)2 All of these big attacks share two important characteristics.

First, all of these attacks are BIG. To be large they must be composed of a large, a very large number of packets. It's very hard to generate substantial traffic with legitimate fully established TCP connections. Instead these record breaking attacks are composed of a very large number of packets not belonging to valid sessions. They are often UDP or arbitrary TCP packets.
It's not uncommon that only one in ten thousand packets hitting our servers is legitimate. Very often the vast majority of packets belong to the attack.

Second shared characteristic shared among the big attacks is that they all begin with an attacker being able to perform IP Spoofing.
But what is IP spoofing?
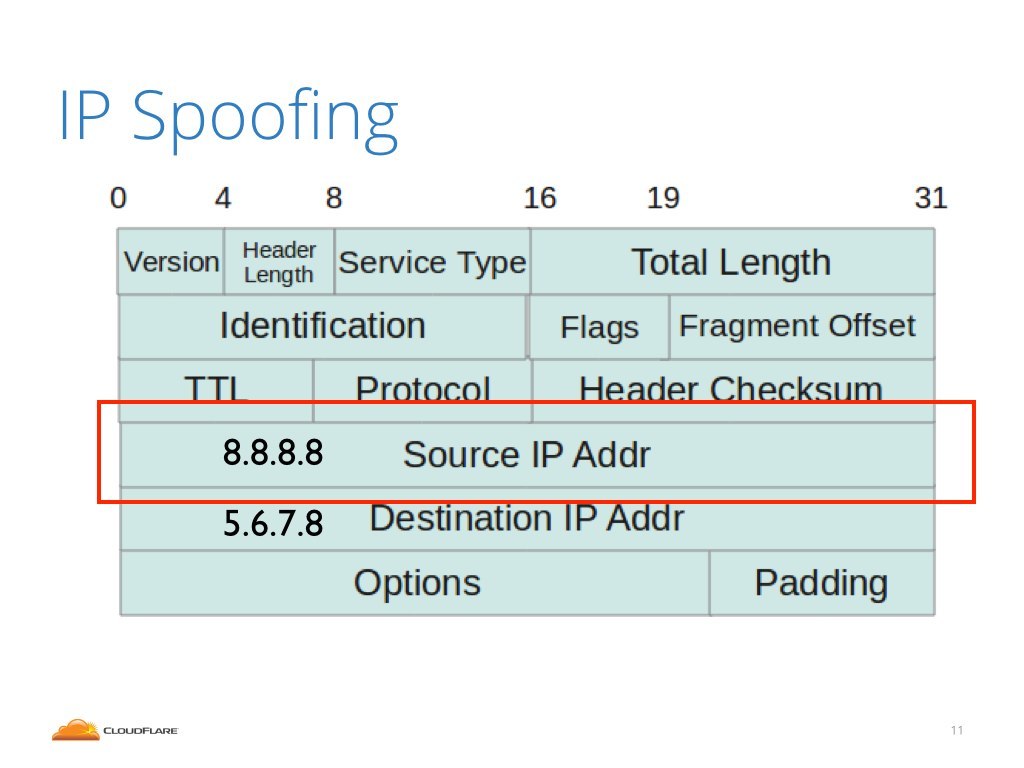
It's a pretty simple thing. In the internet the data is chopped and delivered in packets. Each internet packet contains a header in which there are many of interesting fields, among them the source and destination IP addresses.
But the packet is just a series of bytes and whoever sends it can fully control it. If you transmit one over the wire, you can totally put anything you want inside the packet and inside the headers.
IP spoofing is an idea of rewriting the source IP address. That's it.
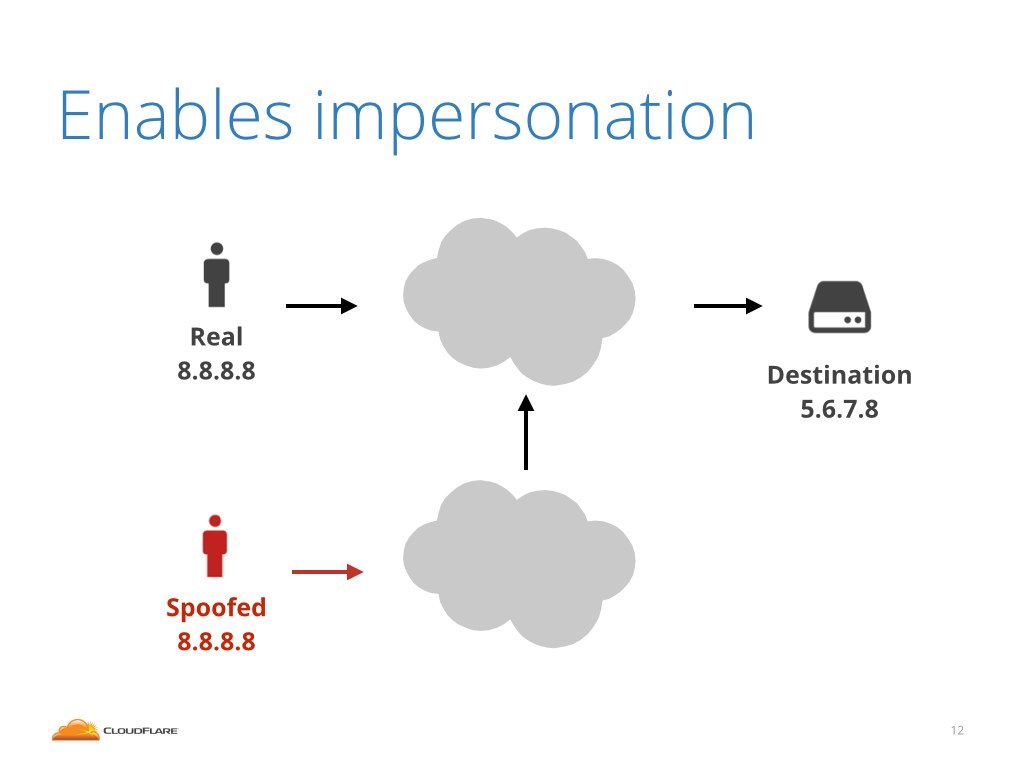
It might sound benign, but in fact IP spoofing is pretty bad.
One of the problems is that it enables impersonation. From the receiving end it's impossible to determine if the received packet was really transmitted by the real host or was maliciously injected into the internet by some impostor.

Long time ago it was recognized that this can lead to significant problems. In May 2000 a famous document was published, called BCP 38. BCP stands for Best Current Practices, it's like an RFC document but a bit less formal.
BCP 38 said clearly - IP spoofing may allow attacks and the internet community must proactively fight it.

Over the last 16 years much progress had been done in this direction, but it's still not fully solved. According to spoofer.caida.org project, still about 27% of the internet service providers do allow their customers to send spoofed IP packets.
Unfortunately this number is not dropping these days. You may ask: why? What is so hard about not allowing spoofed packets to be transmitted?
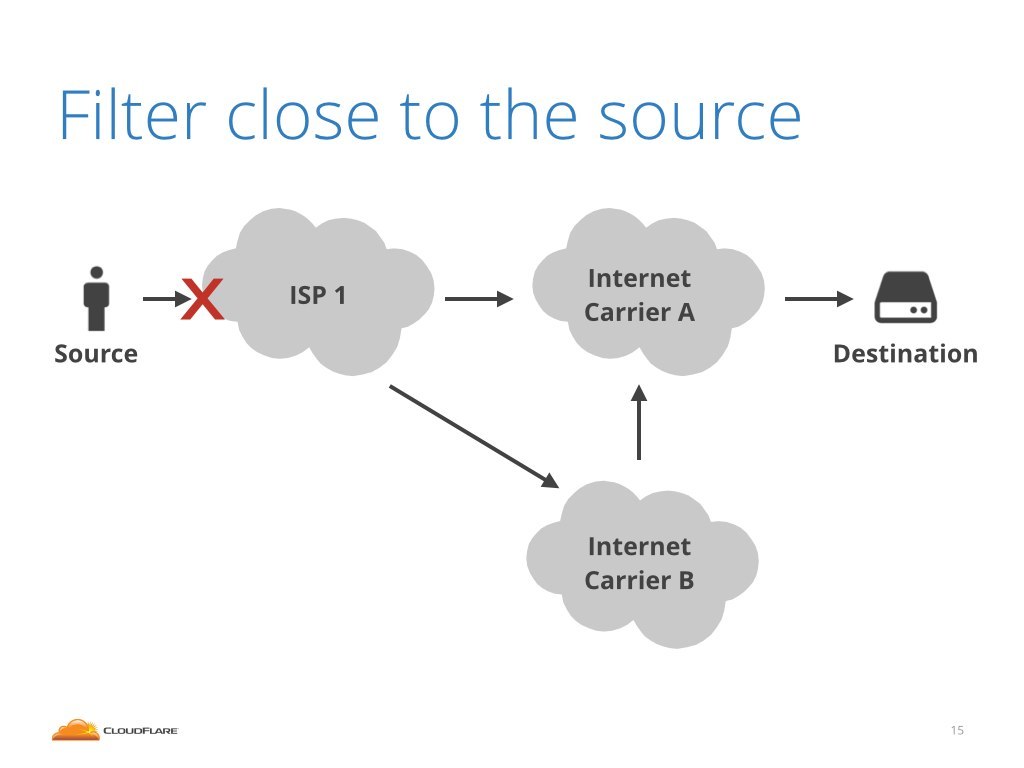
This is a long story, but to cut it short: basically the only way to stop IP spoofing is to do filtering very close to the source, the party originating the packets. If you have a home DSL connection, the filtering will be done on your modem. If you own a server it's the closest switch or router that must filter out the packets with spoofed IP addresses.
This is not always simple. This requires the ISP's to have hardware that can do filtering, then to maintain the configuration. It costs money and expertise.

This concludes the introduction to this talk. I explained what IP spoofing is, that it allows the attacker to impersonate anyone on the internet.
Then I tried to convince you that the IP spoofing is still an unsolved problem. The internet community is aware of it for two decades, but still about 27% of networks allow IP spoofing.

Let's move on and focus now on the properties of the attacks caused by IP spoofing.
Let's start with the first major argument: it's impossible to fight IP spoofing because the attackers are anonymous.
I'd like to show you that on a concrete example. Let me walk you through the steps we do when we want to identify who is behind the attack.
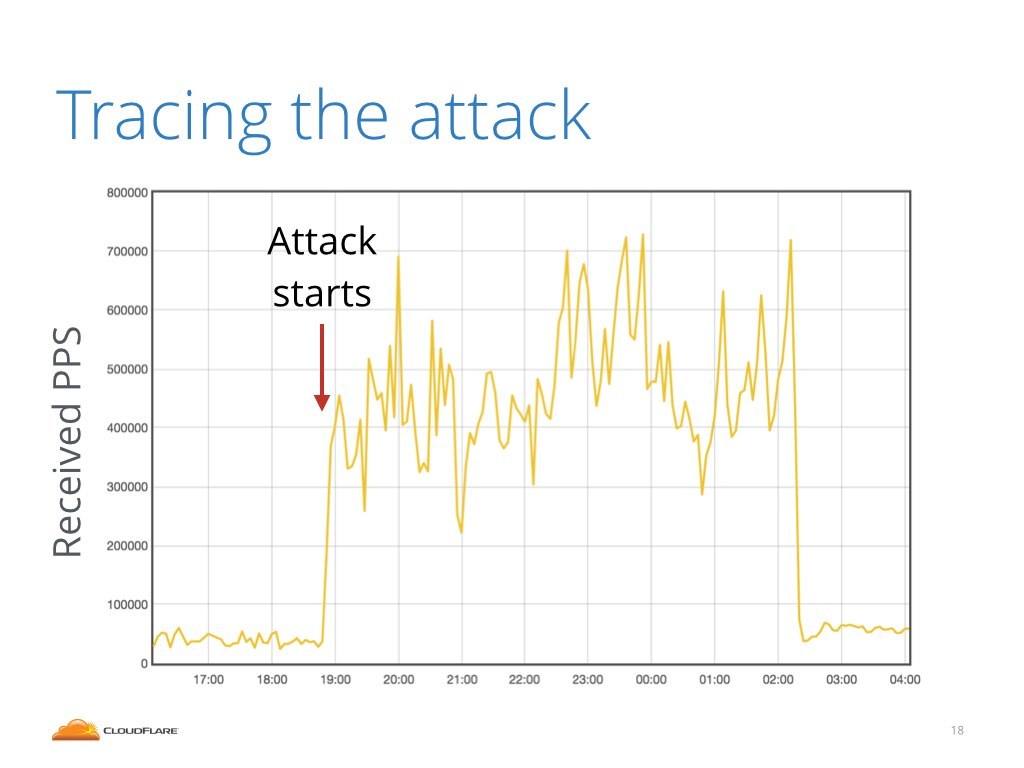
When we are tracing back the attack we start, well, by noticing the attack in the first place. The most obvious way is to look the inbound packet per second charts. Here you can see such a chart of packets per second hitting one of our servers.
During normal operation this server was receiving about 50 thousand packets per second (pps), and then the attack started hitting above 400 thousand pps. A significant increase.
The first step is to figure out what is hitting us.
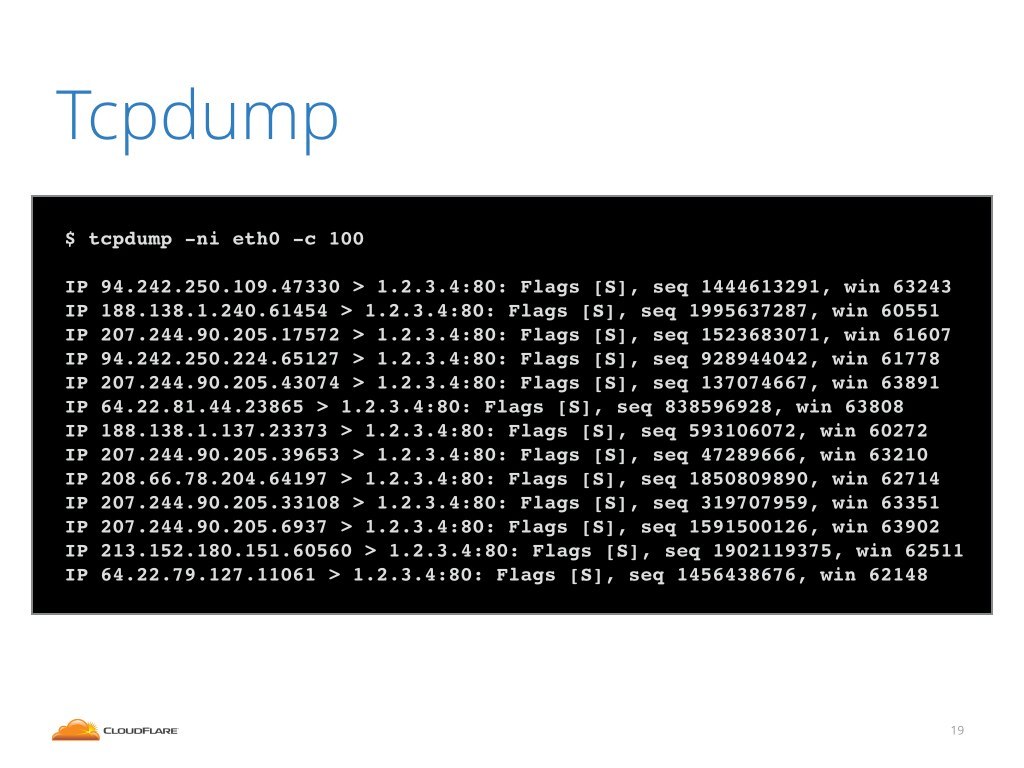
To do that we log in to the attacked server, and run a tcpdump to
see what packets are delivered. In this case it was a SYN flood, that
is a flood composed of TCP packets with SYN bit set. If you look
carefully you might notice the source IP's look random - they might
have been spoofed.
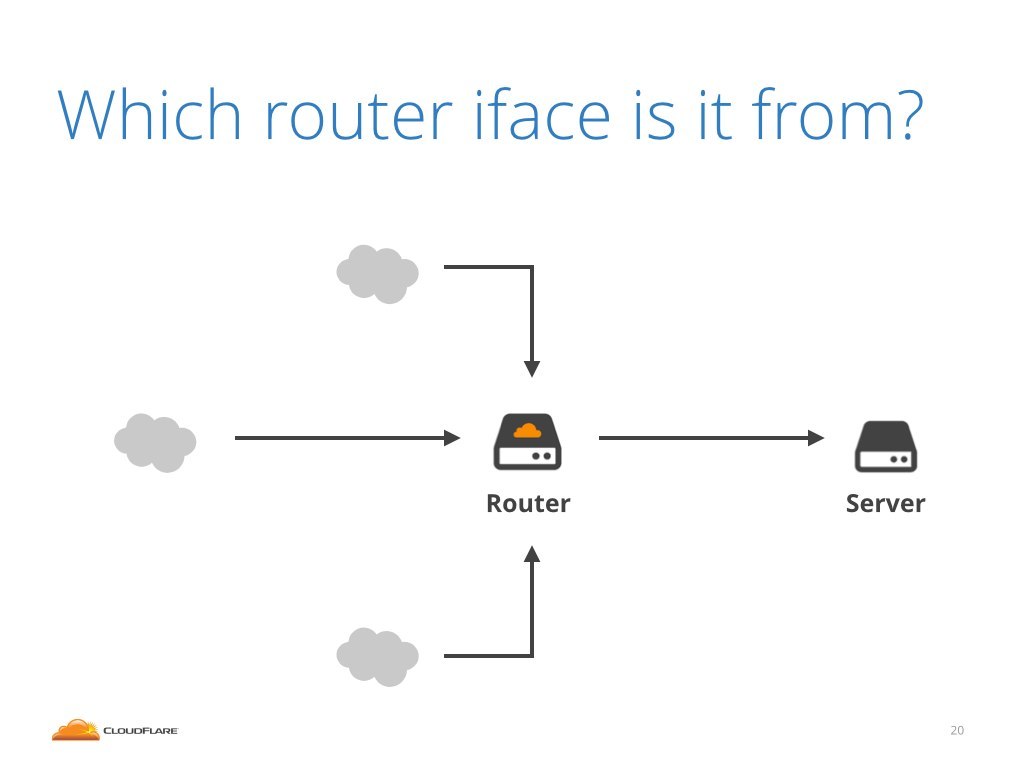
Now we know what is hitting us. The next question is: where it came from? How the attack reached our routers?
To do this we look at our router and try to understand out of which interface the attack came from. Our routers have many interfaces, connected to multiple parties on the internet. Which one sent us the attack?
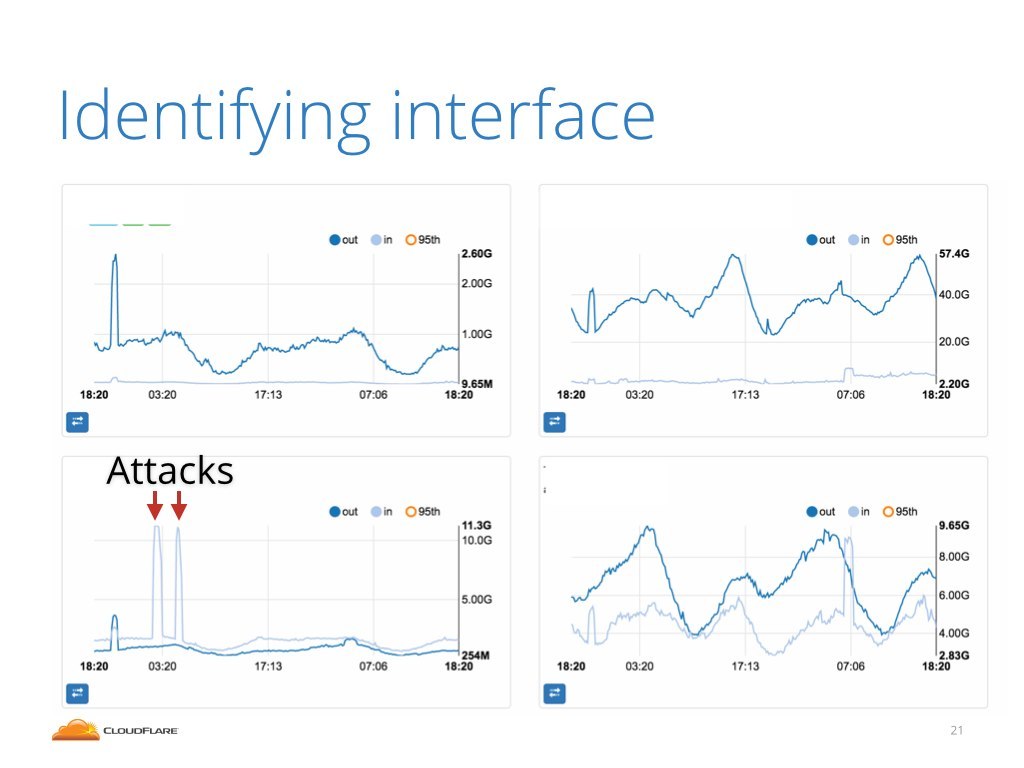
To identify this we need to inspect our router charts. Here's an example screenshot showing charts for four interfaces. In the bottom left corner you can see two big, 10Gbps, spikes of inbound traffic. This pattern usually indicates an attack. In this case the attack was coming from that interface.

Who is on the other side of this interface? We need to identify where the physical cable leads to and who is sending the malicious traffic.
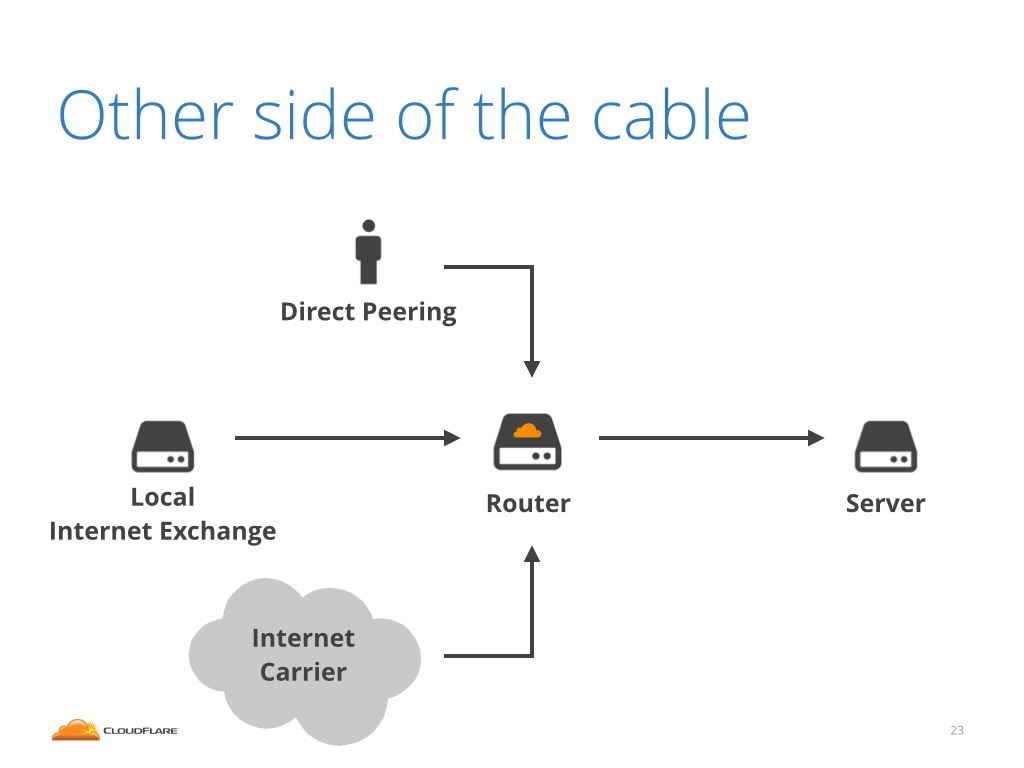
Generally speaking there are three categories of connections coming to our routers. The attack might have come from any of them.
First, there are a "Direct Peering" also called "PNI" connections. These are the cables that go directly to some other big internet entity, for example it could be Google, Amazon, Linode or maybe Digital Ocean.
Second category of cables are the cables that connect us to local internet exchanges. An internet exchange is a local community of mostly regional internet service providers. Internet exchanges are run in most major cities.
Finally, there is the connectivity that connects us to the internet. We can't reach the public internet over direct peering nor over local internet exchanges. To send traffic outside of the current region we need to be connected to an internet carrier, sometimes called internet transit or upstream. This is a paid service that allows us to connect to the public internet.
Ok, let's start with direct peering. What happens when we see a large attack coming from the direct peering interface?
This is a simple story. We pick up a phone and call the other party. There is no further investigation needed, in this case there is no other internet entity involved. It's clear who sends us the malicious traffic.
In the direct peering case the story mostly finishes there. It's in the interest of both parties to identify the attack source and solve the problem. We are directly connected only to competent internet players, and the communication is usually very good. Any problem is quickly fixed.
This was easy. How about the other two remaining types of connections?
What happens if the attack is coming over an internet exchange or internet carrier link?
Unfortunately it's not that simple. The sad truth is that we can't do anything about the attack. We have no way to report it and no way to fix it in the long term. Let me explain.

Let's start with internet exchanges. As I mentioned, an internet exchange is a community of regional ISP's. An exchange is pretty much a big Layer 2, Ethernet switch. This is a photo of an exchange in Seattle. As you can see it's a big switch with plenty of Ethernet cables.
These cables go to routers belonging to exchange participants. One of the cables goes to our router. When we see an attack, from the router point of view, it would be coming over the internet exchange interface.
Sadly this is all our router can tell us. The router has no idea who exactly over the exchange had sent malicious packets. All we see is that packets are delivered via the exchange, no more details.
This is because routers are optimized to routing packets and look at IP header. The data on who transmitted the packet is embedded in Layer 2, the Ethernet frame, but mainstream routers can't really inspect that.
Unfortunately, this means that when we receive an attack coming from exchange, there is nothing we can do. We don't know which of the local ISP's is behind the attack. We don't know who is responsible for the attack.
Ok, how about the internet carriers case? Maybe at least they can help us to identify the attackers.
Unfortunately no. Let me show that on a concrete example.
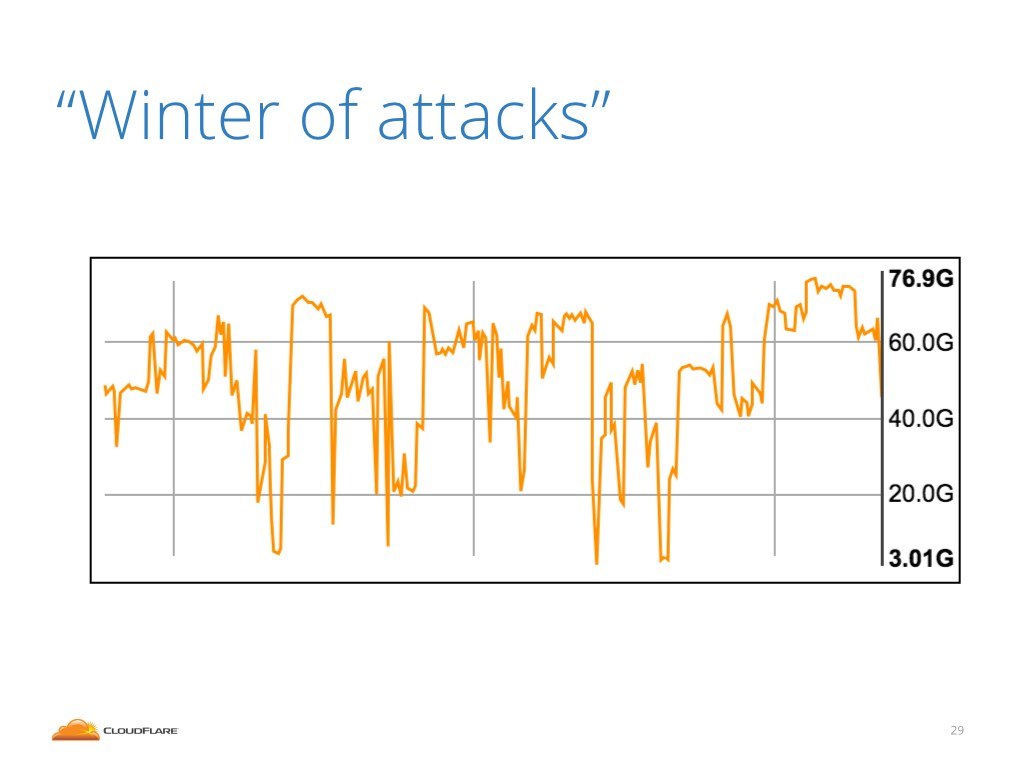
Earlier, in March this year we published a story about particularly interesting attacks. We named it the "The winter of attacks".
This is one of the charts we published. It shows inbound traffic on one of our router interfaces. During the incident this particular router, over this particular cable received about 80Gbps of attack traffic.
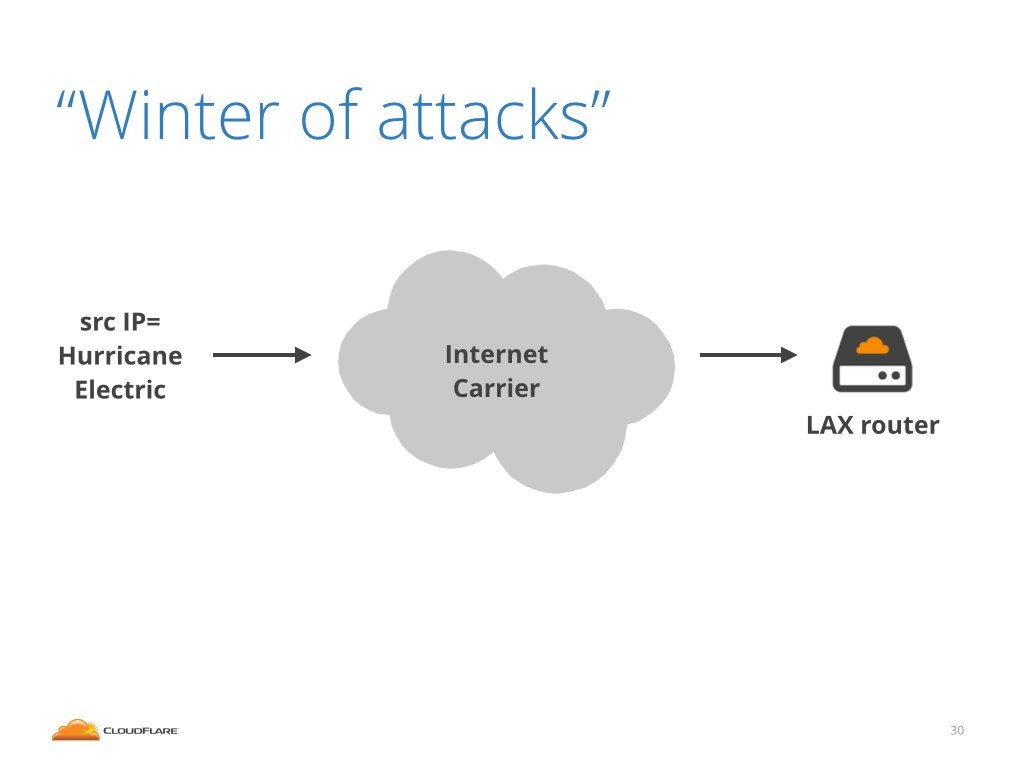
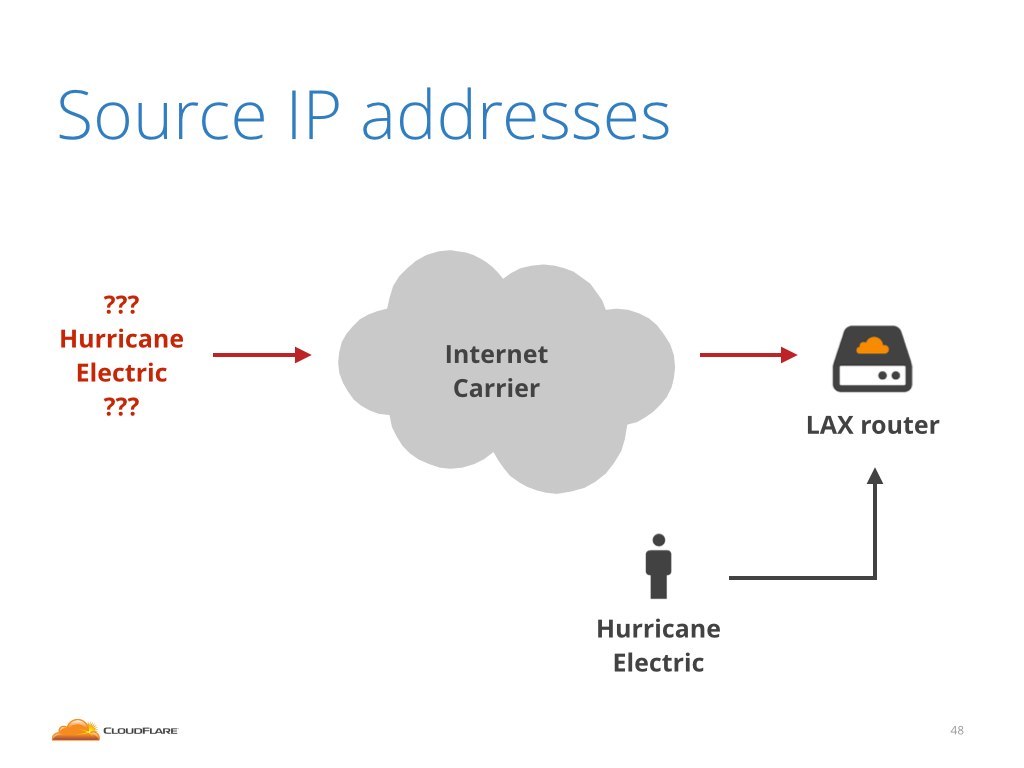
The interface in question was connected to our internet carrier in Los Angeles. We noticed an interesting characteristic of the attack traffic. The source IP addresses of the packets were set to Hurricane Electric IP ranges. Hurricane Electric is another big internet provider.
Looks like Hurricane Electric attacking us, right?
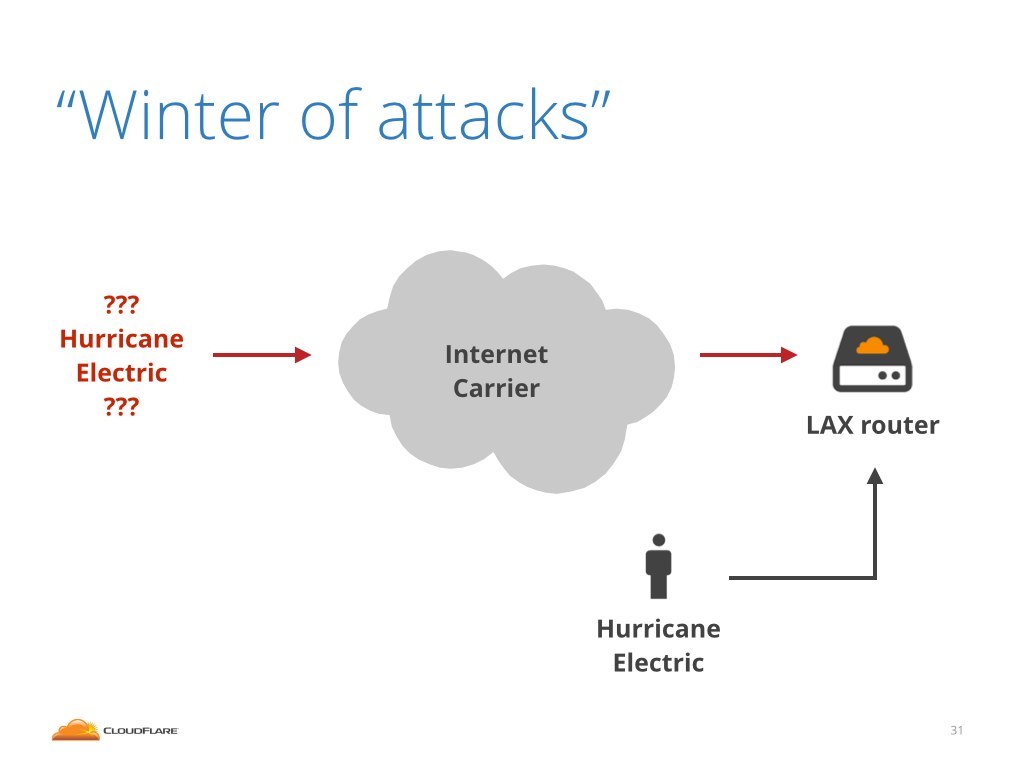
Not in this case. This is because we actually had a direct connection to Hurricane Electric in this very data center. If the attack was really launched from Hurricane Electric, it would come over different interface.
While it is technically possible that the attack could have been originated at the Hurricane Electric network, and got transmitted over a public internet, it is highly unlikely. It would have cost them plenty of money and indicate a fairly broken routing within their network.
What most likely happened, is that one of our internet carriers customers was spoofing IP addresses and was impersonating Hurricane Electric.
We called up our carrier and explained the situation, but without much success. They raised two issues. First, they can't proactively know that this traffic was indeed spoofed IP traffic. From their point of view the traffic might well have been legitimate. Second, they don't have good insight into their network and they really, technically, don't know who of their customers is transmitting this data.

This all leads to a conclusion that for the majority of attacks using IP spoofing it's impossible to trace back the attacker. It's impossible to figure out just who sent the malicious traffic.

Let's move up to second major argument:IP spoofing allows sophisticated attacks.

I'll try to show three examples of attacks with gradually raising complexity.
Let's start with the details of the "Spamhaus" DNS amplification and why IP spoofing allowed it.
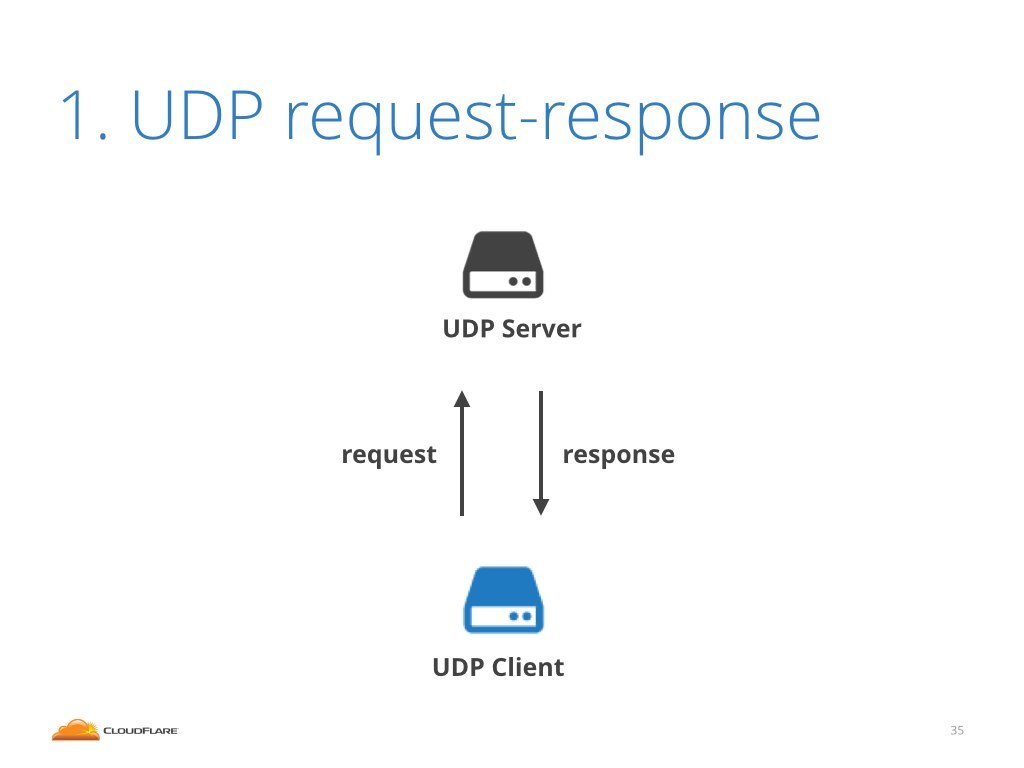
In order to explain amplification, we need to step back first. Let's talk about a protocol design.
Let's imagine a simple request-response protocol using UDP as the transport layer. The client asks some query, the server responds with an answer. This is for example how DNS and NTP work.
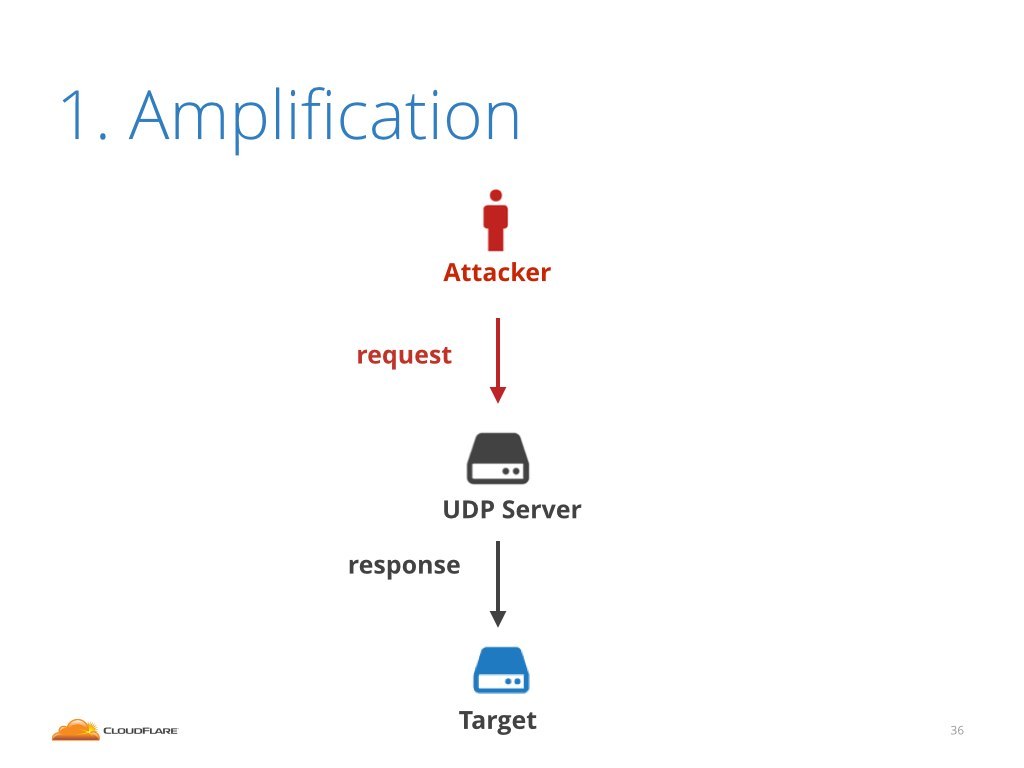
The idea of amplification comes from abusing this design. The attacker fakes the request packet, and tricks the server into treating it as legitimate request. The server, unaware of the real source of the request, parses it and with all the good will sends the response to the target. But target never really asked for this data!
This may not sound like a big deal, until you realize that often the response packet is much larger than the request!
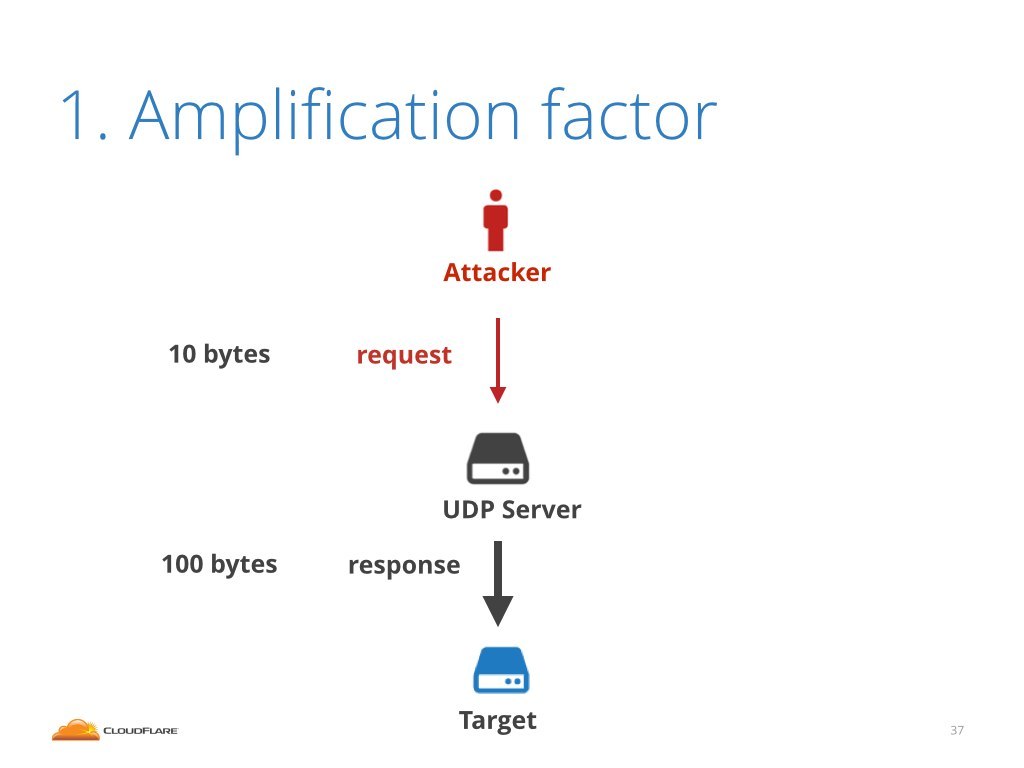
For example, it's pretty common in DNS protocol that the request is trivial, consisting of only couple of bytes. While the answer is large with hundreds of bytes of payload.
This is the idea of amplification. Instead of sending traffic directly hassling the target it is possible to generate much larger bandwidth by bouncing out of some server.
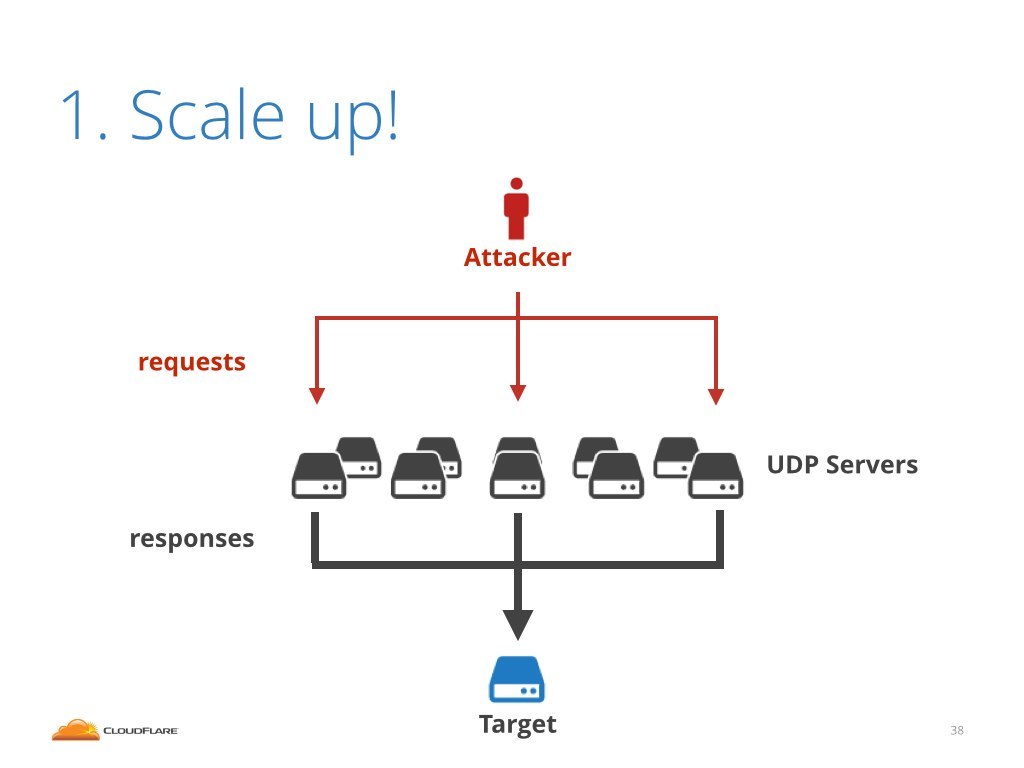
Bouncing off one server won't generate much load. But it's possible to scale up the attack and use an army of exposed UDP servers!
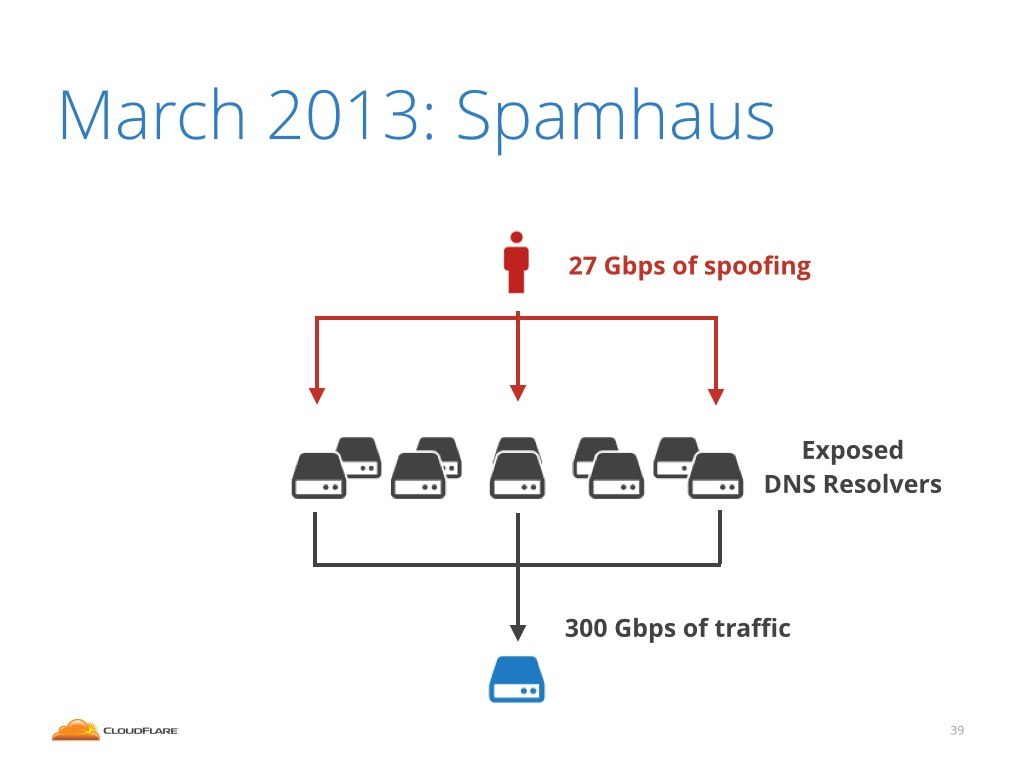
This is exactly what happened in March 2013. Back then we were hit by a very large attack directed at Spamhaus. We estimate that the attackers had access to three servers with 10Gbps connectivity. In total they had 30Gbps of IP spoofing capacity. They were able to amplify this power by bouncing off exposed DNS servers. In the end this generated 300Gbps of traffic hitting our servers.

But I'll claim that amplification is not the most sophisticated type of attacks these days. First, they're fairly easy to block on firewall. Blocking DNS amplifications is as simple as dropping unwanted DNS answers by filtering packets coming from port 53.
Furthermore there are number of initiatives on the internet that try
to clean up exposed servers which could be used for
amplifications. There is the openresolverproject.org that tracks exposed
DNS resolvers, then there is openntpproject.org looking for
vulnerable NTP servers. And finally there is the shodan.io search
engine, which scans the internet and is often helping the ISP's to find
exposed servers in their IP ranges.

Let's move on to second attack example. Let's discuss the details of the "Winter of attacks" mentioned before.
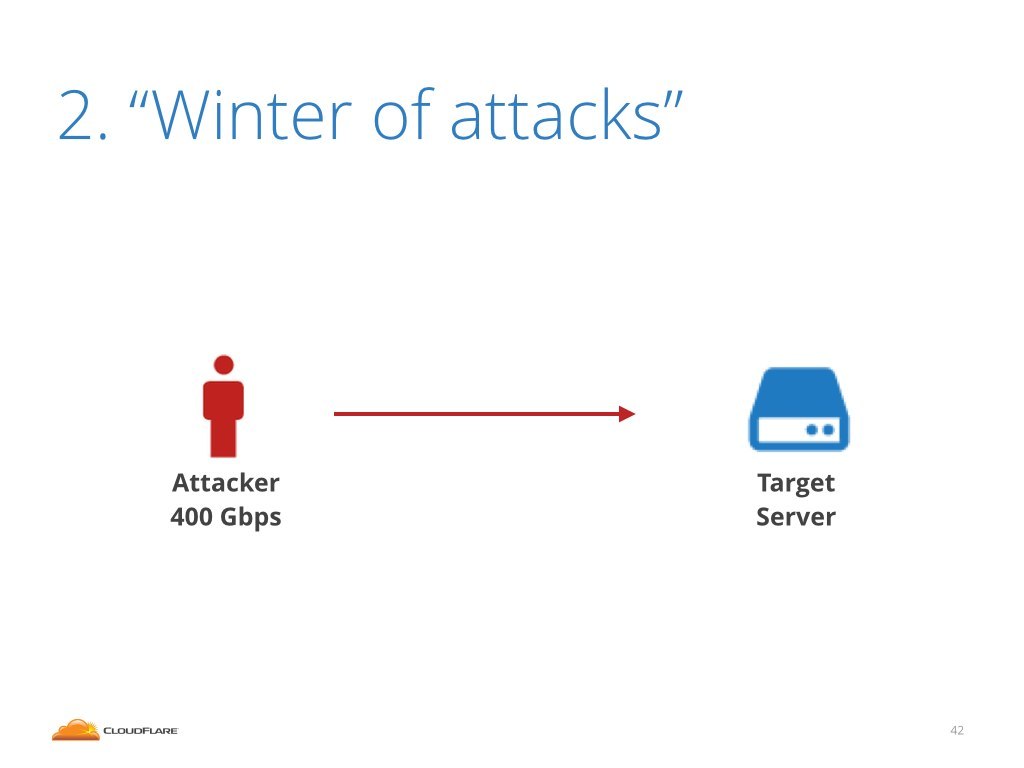
This time the attacker didn't use any amplification, but instead sent spoofed traffic directly against our servers. The attack volume was pretty large.
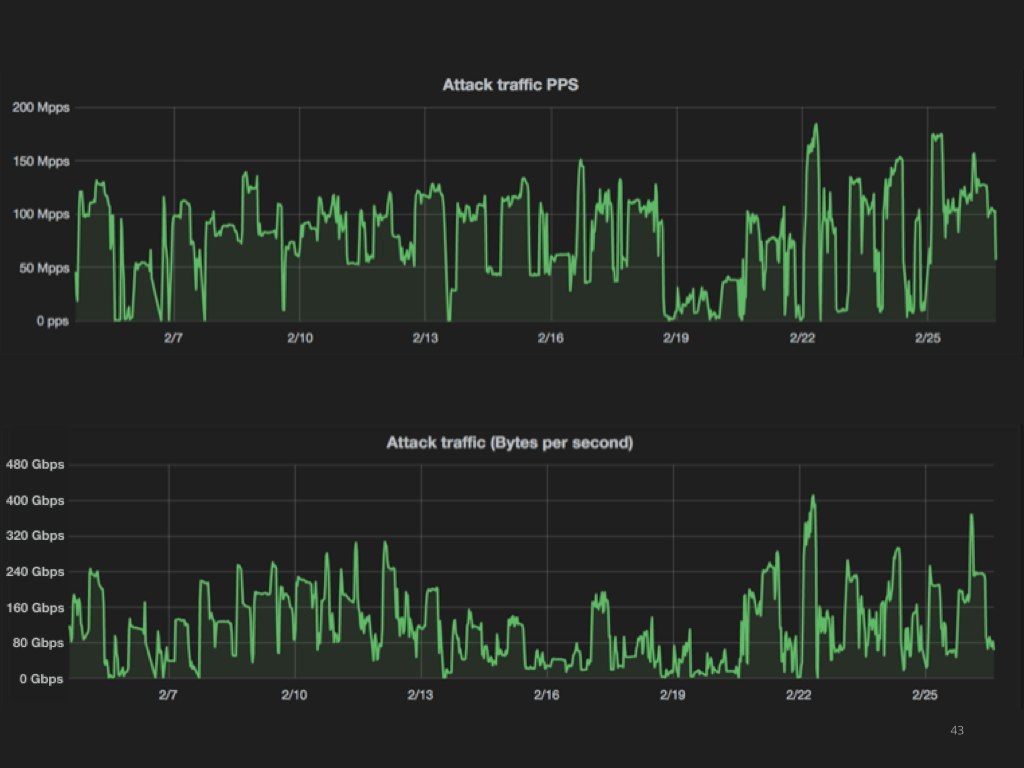
These are the charts we published. In the bottom one you can see inbound bandwidth, topping at about 400Gbps. On the top chart you can see the packets per second metric, going up to 150 million packets per second.
You can only imagine what would happen if your servers received 150M pps. They would most likely boil.
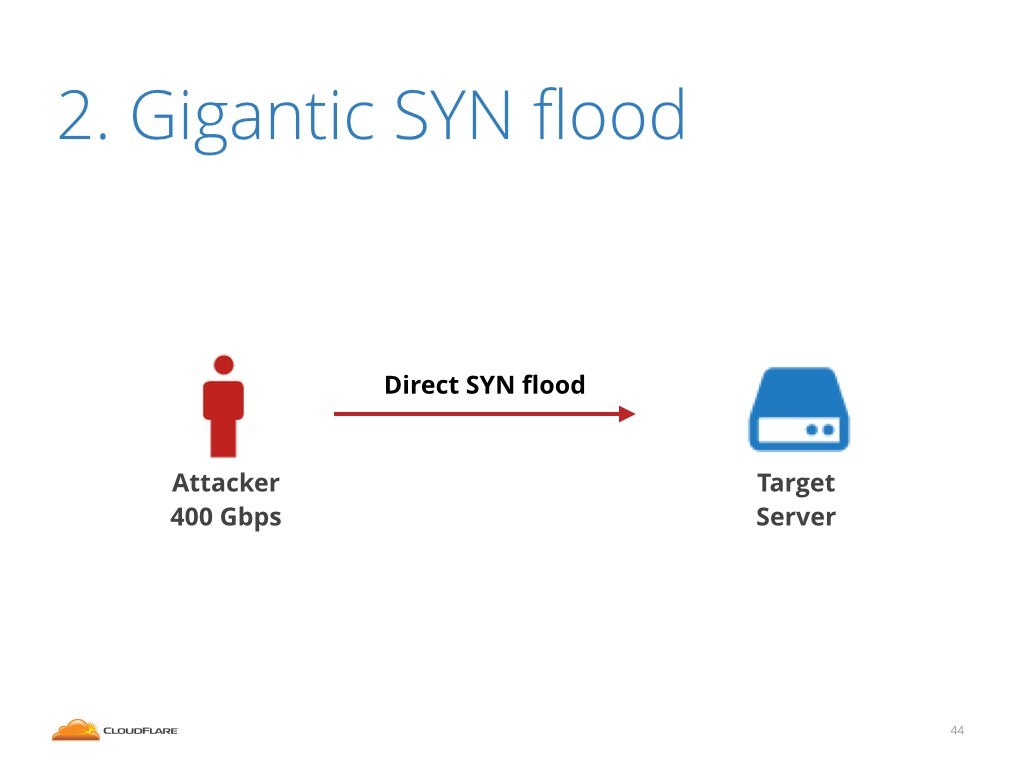
In this attack type, the packets were sent directly against us. This means the attacker could choose whatever payload he wanted. The attacker wasn't limited to crafting DNS or NTP.
In this case the attack was composed of SYN packets. SYN floods are particularly nasty since you can't just block these packets on firewall. SYN packets are part of the TCP handshake and dropping them indiscriminately is not a good idea if you want to keep serving valid traffic.

To be able to distinguish valid from attack packets we need to use much more precise methods than common firewalls. We found BPF bytecode to be a very effective tool for that.
Here you can see an example of Linux firewall iptables
rule using a BPF bytecode. BPF is this series of numbers.

What are these numbers? Well, you can decompile them and print them out in text form. Here's an example view. As you can see this looks very much like assembler opcodes, it's because it is! With BPF we can create simple programs and run them within the Linux firewall. This allows us to perform deep packet inspection and express a fairly sophisticated filtering logic as part of a firewall.

We found this method very effective, and we created a couple of scripts to help us with generating the BPF. We open sourced them, and you can find this in our "BPF Tools" Github repo.
We shared scripts that generate BPF's for DNS and for SYN floods. Maybe you will find these useful.
But what about source IP addresses? We've already mentioned that in this particular attack we saw packets spoofed with Hurricane Electric IP ranges. What about other attacks? Is there anything interesting in the source IP address field?
Let me show you couple of examples of some other attacks we saw recently.
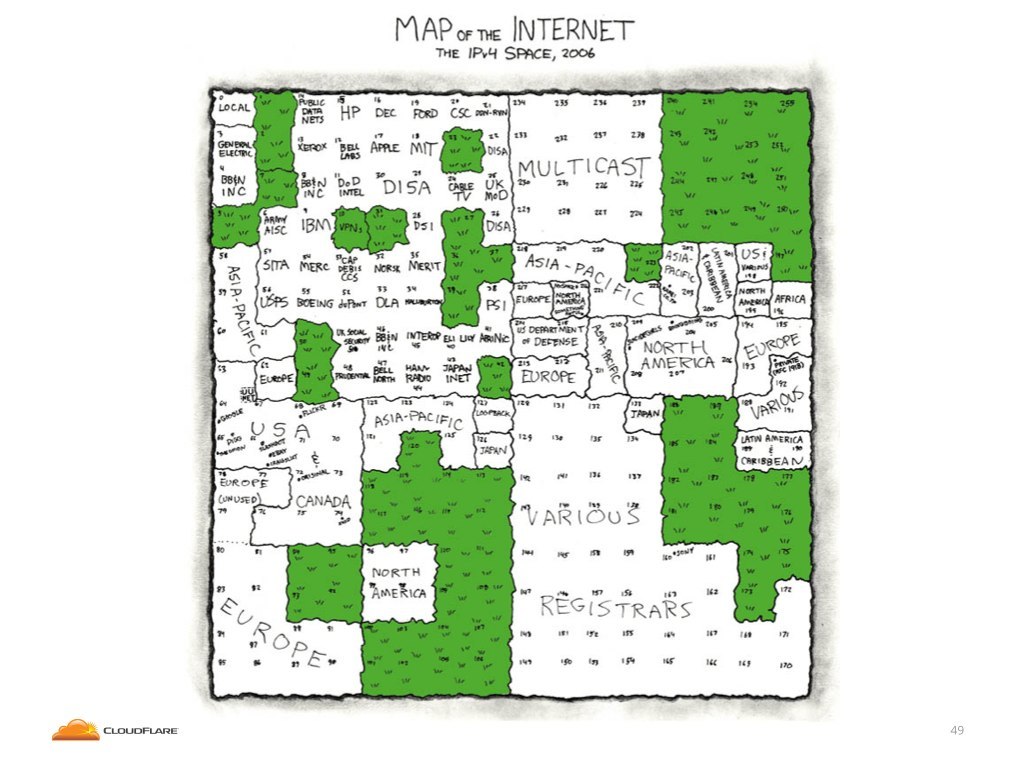
Before we go deeper I owe you an explanation of what you will see. This is a famous XKCD from 2006, when Randall drew a pretty map of IP addresses. He tried to draw every netblock and name its owner in a very pretty way. Visualizing IP addresses in two dimensional space is not easy, so Randall didn't drew it linearly. Instead he used something called a Hilbert Curve, which is a fancy way of drawing one dimensional space, like IP addresses, on two dimensional map, in such a way that numbers close to each other in binary code will be drawn close to each other on the map.
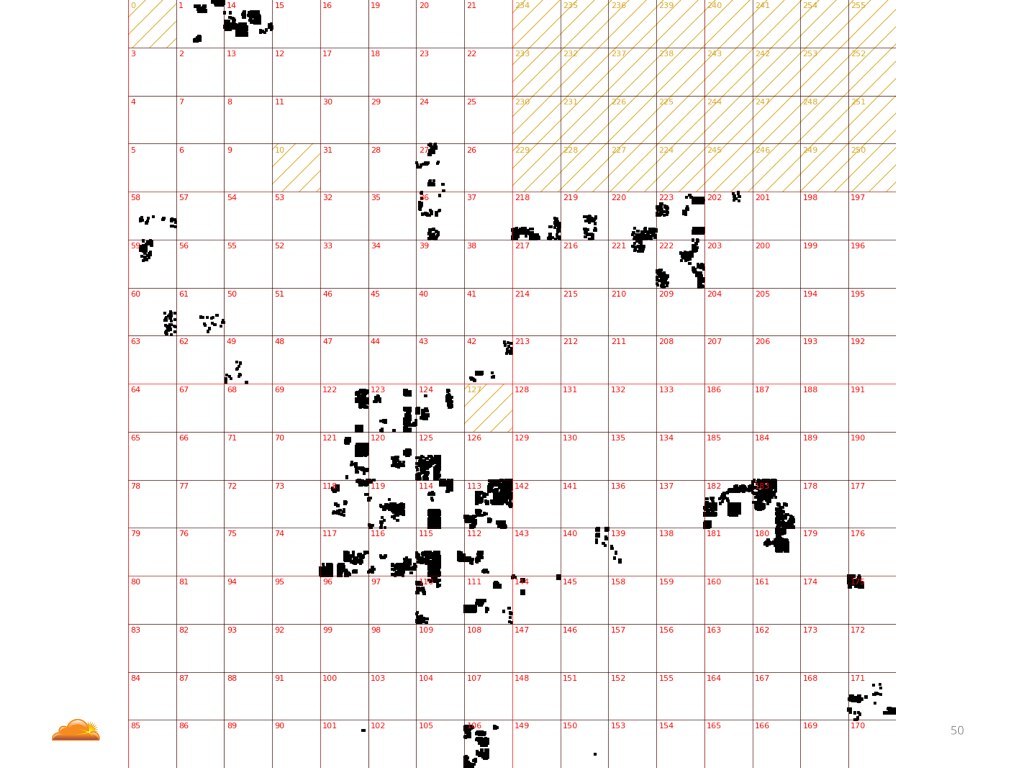
This is an example of what we saw during one of the attacks. Each black pixel represents an unique source IP address we saw used in this particular attack.
As you can see this attack was coming from a number of small "islands" of IP addresses. Does it mean the IP addresses were spoofed? We don't know, we can't say that with confidence.
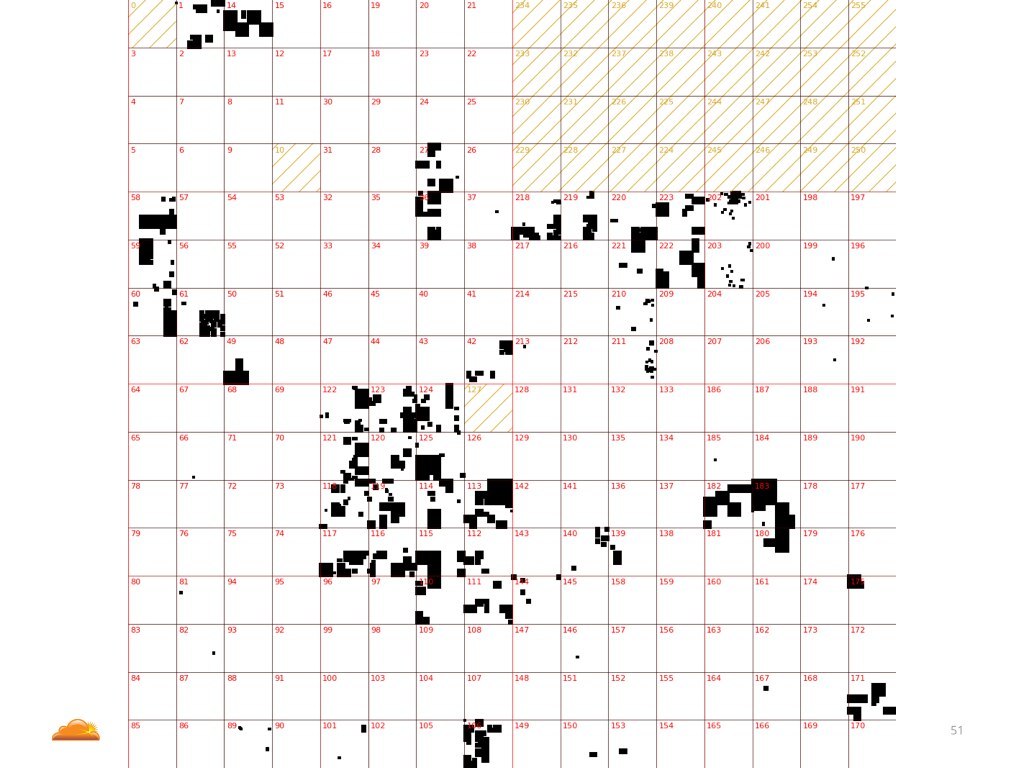
But what we can say, is that this is a map of IP ranges belonging to an ISP called China Telecom.
Once again, previous chart shows IP's used in attack, this one shows all IP's belonging to China Telecom. What is the moral? I don't know. There are two ways of interpreting this.
One: someone has a very large botnet which seems to contain only devices in China Telecom network. Furthermore it seems the bots are evenly distributed across all the China Telecom IP ranges. This is possible, I guess.
Another interpretation is that someone looked up IP ranges belonging to China Telecom and spoofed their IP's with uniform probability.
Which one is correct - I can't tell.

Let's move on to my favorite example. In this case the attacker was generating source IP addresses uniformly from the whole IP address space. From 0.0.0.0 to 255.255.255.255. Including all the reserved IP blocks.
For example in the middle there is a 127.0.0.1 block.
So if you ask us "do you see attacks from localhost?" the answer is: yes, absolutely! Every other day we see 127.0.0.1 attacking us!

Another one. This time the reserved /8 netblocks were not part of the attack. But why? I don't know. Either the attacker was smart to avoid generating obviously wrong IP addresses, or maybe their ISP filtered the invalid /8 blocks for them?

Yet another profile, this one is spoofing only IP addresses with highest bit set in the most significant IP address byte. I'm not sure why this pattern was used.
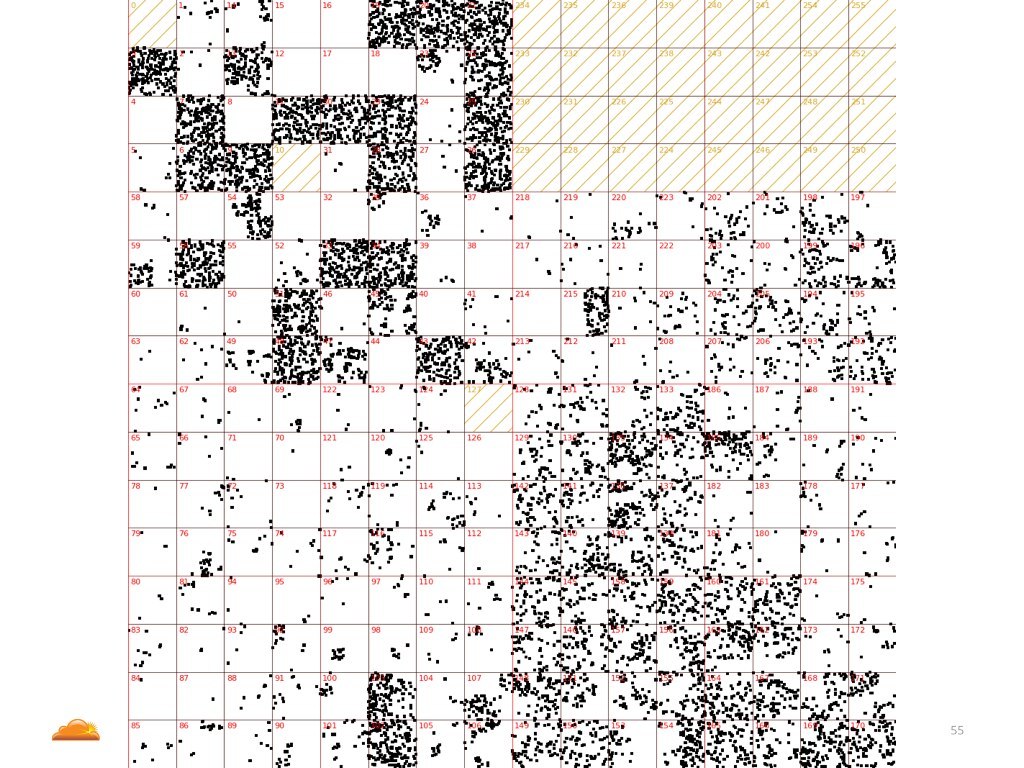
Here is my favorite one. On first glance this might look like IP addresses belonging to some real, big ISP's. This is how non-spoofed traffic might have looked like.
But this is not the case. In fact, the completely opposite is true. What you see here is IP addresses that belong to ranges which are not routable on the public internet. Someone went through quite a bit of trouble. He had to scrape the public routing tables, figure out what net blocks are not present on the public internet, and only spoof these IP's. Fairly fancy idea.
This concludes the discussion on patterns of source IP's used in attacks.
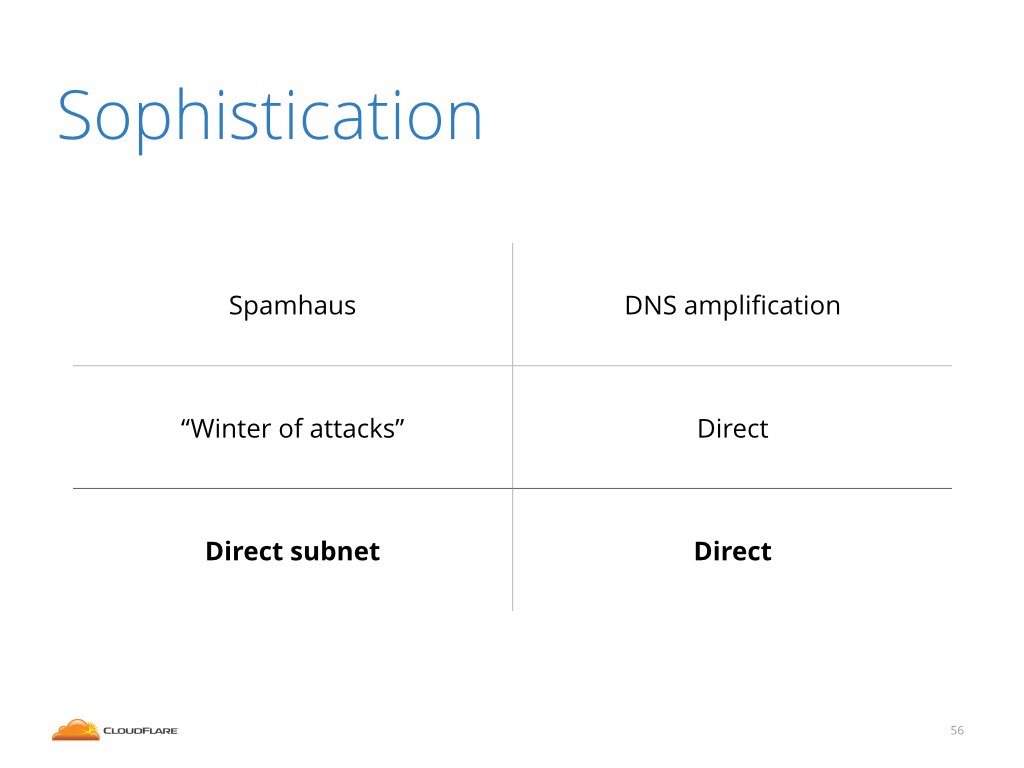
Let's move on to the last type of attacks I want to discuss. The "Direct subnet" attacks which we only noticed in June this year.
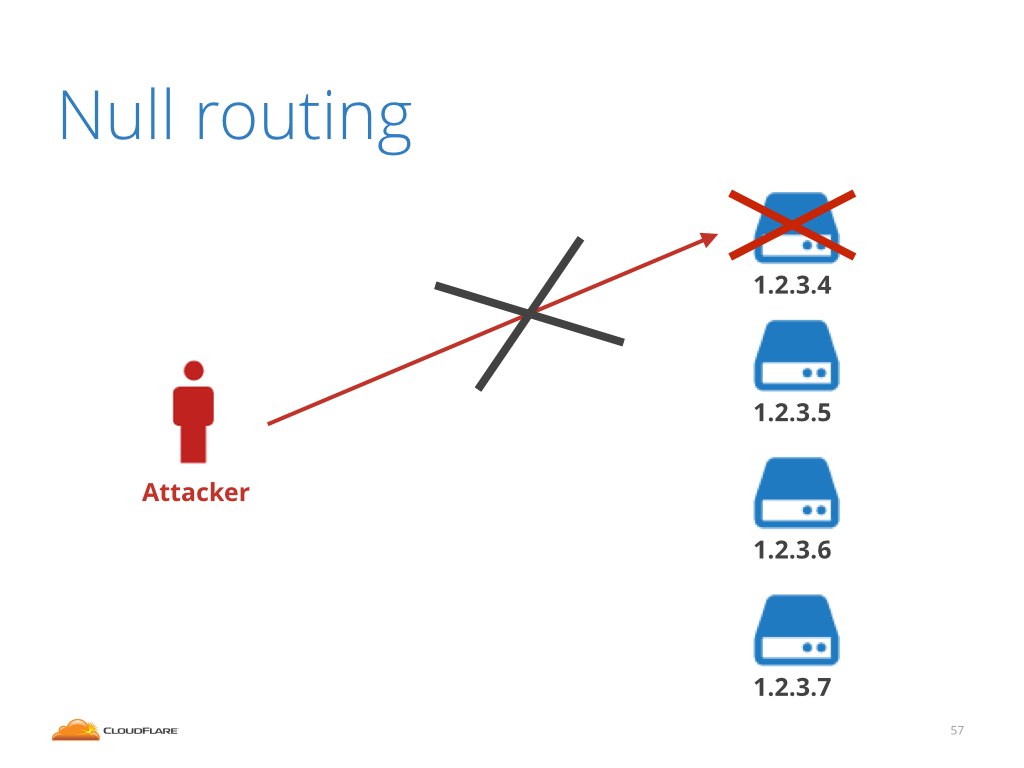
In order to explain the severity of these attacks I first need to explain the usual mitigation strategy for big attacks.
In a situation when a big attack occurs, the administrators of the target website often have little choice but to remove the target IP address from the internet.
This is possible via BGP Nullrouting also called Blackholing. BGP is the protocol that internet routers speak to each other.
During big attacks when the target has insufficient bandwidth, a network congestion will occur. This is bad and affects not only the targeted IP addresses but the whole target network. Sometimes to save the body you need to sacrifice the limb.
With BGP Nullrouting it is possible to pretty much remove target IP address from the internet and therefore relieve the congestion. This is the tool of last resource.
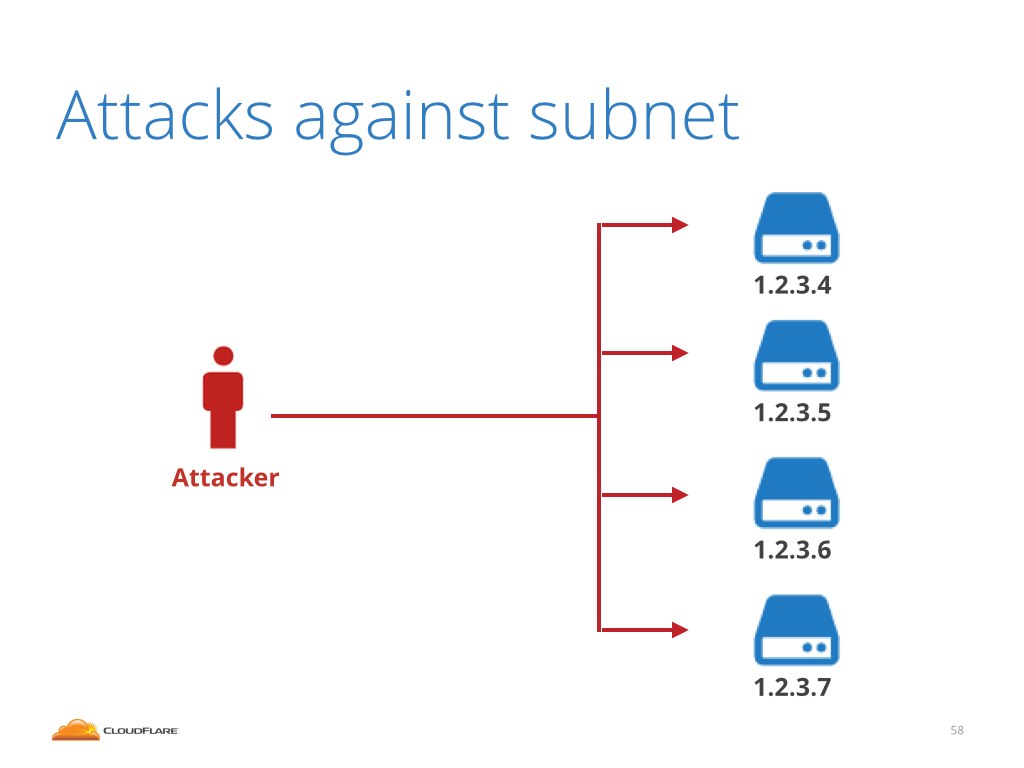
In June we saw a very dangerous type of the attack. We saw a big flood of packets directed against the whole subnet, not against a single target IP address. This is highly unusual. Normally the attacks target only a couple addresses.
This is also extremely dangerous. With 255 IP addresses attacked it is not technically possible to perform nullrouting. This renders the DDoS mitigation method of last resort useless.

This leads us with a sad conclusion that the only way to survive big DDoS attacks is to absorb the traffic.
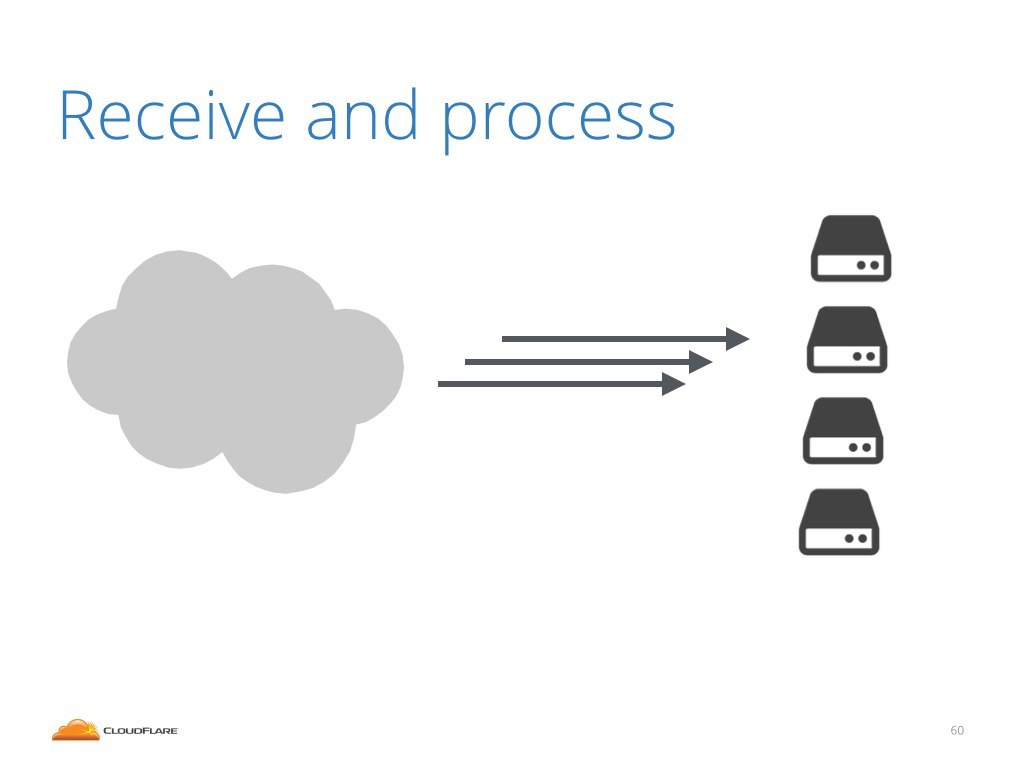
The only way to keep services online is to have enough network capacity to receive the attack, and enough processing power to be able to process and filter all the packets.
Unfortunately bandwidth and hardware are expensive. Furthermore these resources will mostly stay idle, being utilized only during big attacks.
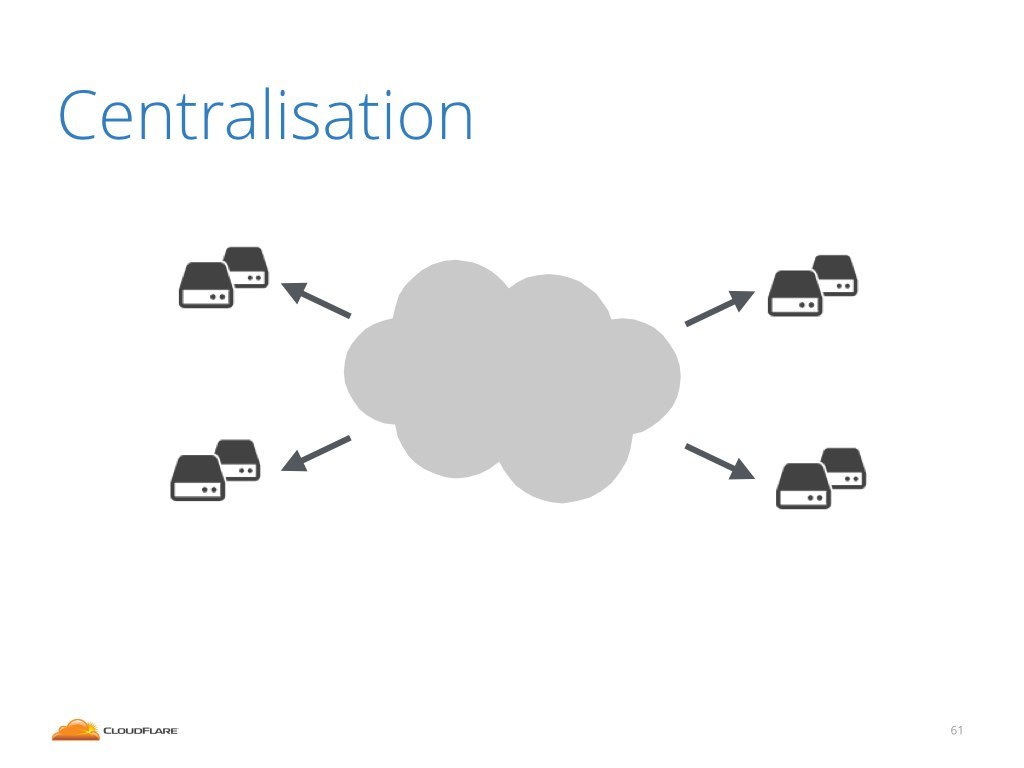
This is one of the forces that causes centralization in the internet. In order to stay online, serious websites must use some kind of DDoS mitigation service. There are only a couple of big such providers on the internet, and they have enormous leverage.
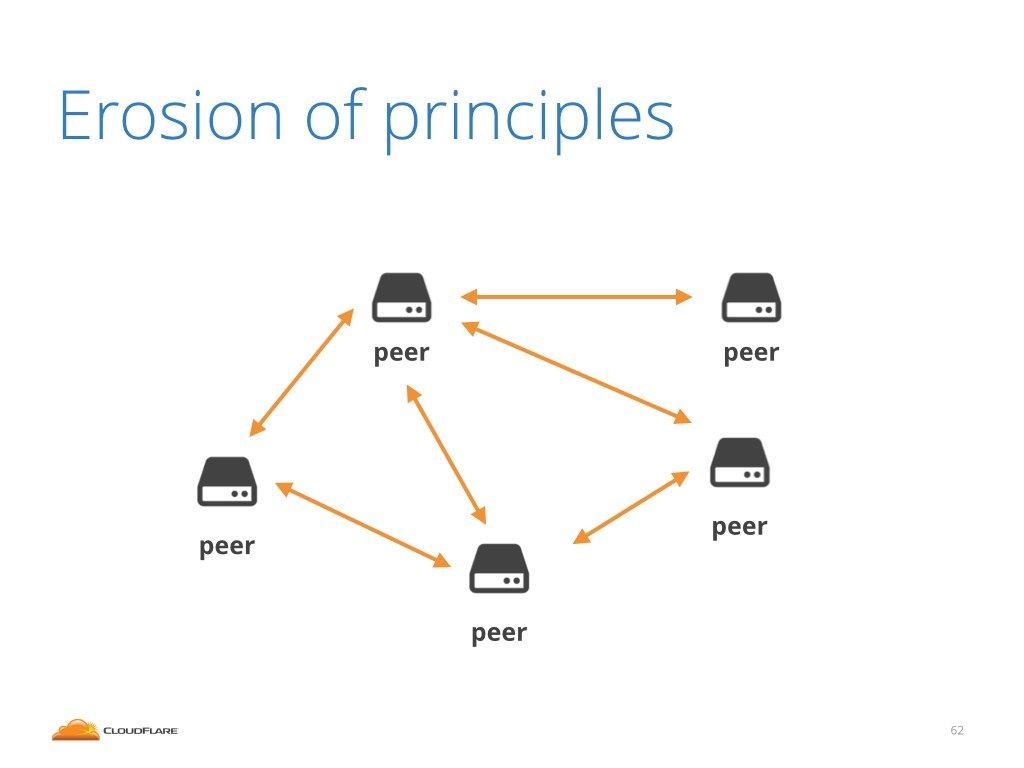
This is not good and I believe it erodes the principles of the internet. The internet was originally created as a collection of equal connected peers. Everyone connected had equal rights, could consume content, produce content.
It was normal to host DNS or HTTP services on your home land-line.
But this is not possible anymore. It's just too easy to knock unprotected websites off line.

We described the problem and painted a pretty grim look for current state of the situation. Is there any way to solve it?
I believe there is.

First we need to agree that the technical solutions to solve IP spoofing had failed. The internet community created the BCP 38 document 16 years ago, and we still have 27% of network providers allowing IP spoofing.

The reality is that we must learn to live in a world where IP spoofing is an unavoidable fact.

I think the internet community tried to solve the wrong problem.
Instead of focusing on IP spoofing we should have focused on a broader problem: the attribution. I really don't care what bits are in the source IP field of the attack packets. What I want to know is just who is attacking me.
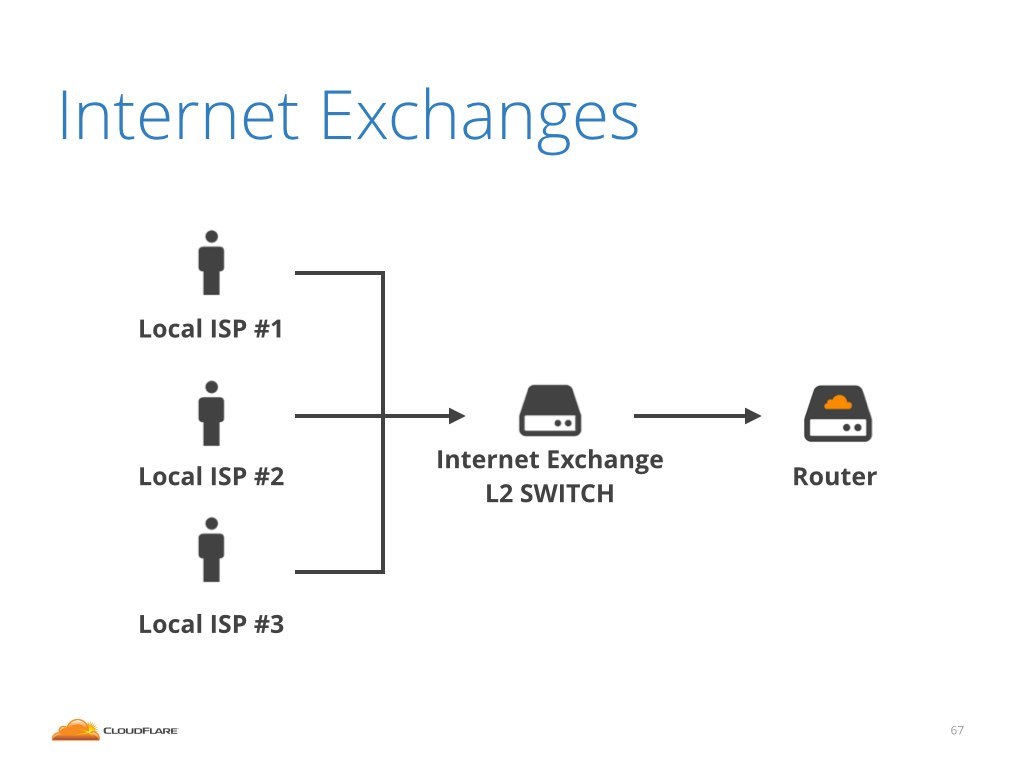
I would love to get support of internet exchange operators. Please help me out with identifying which of the connected peer is transmitting the majority of attack packets.
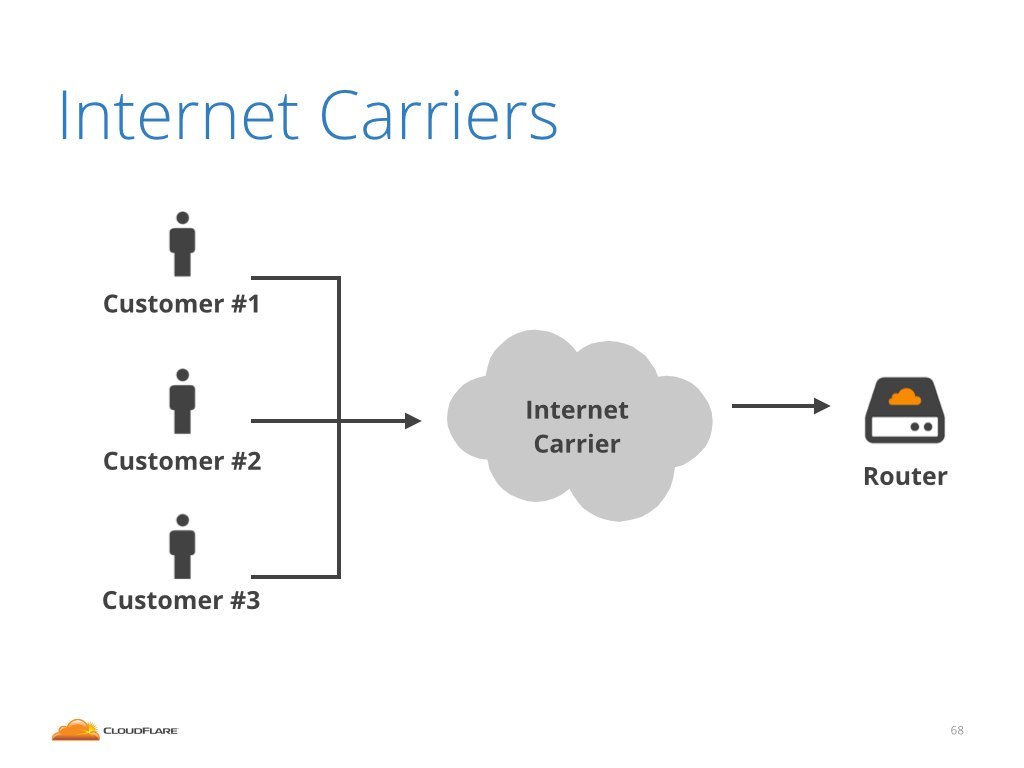
The same goes to internet carriers. I'd like them to contribute and help with identifying which of their customers transmitted the attack.
But how to do this? We've already said that the internet carriers often lack any insight into their network.

Well, they should just use netflow.
Netflow is an awesome protocol supported by all major router vendors.
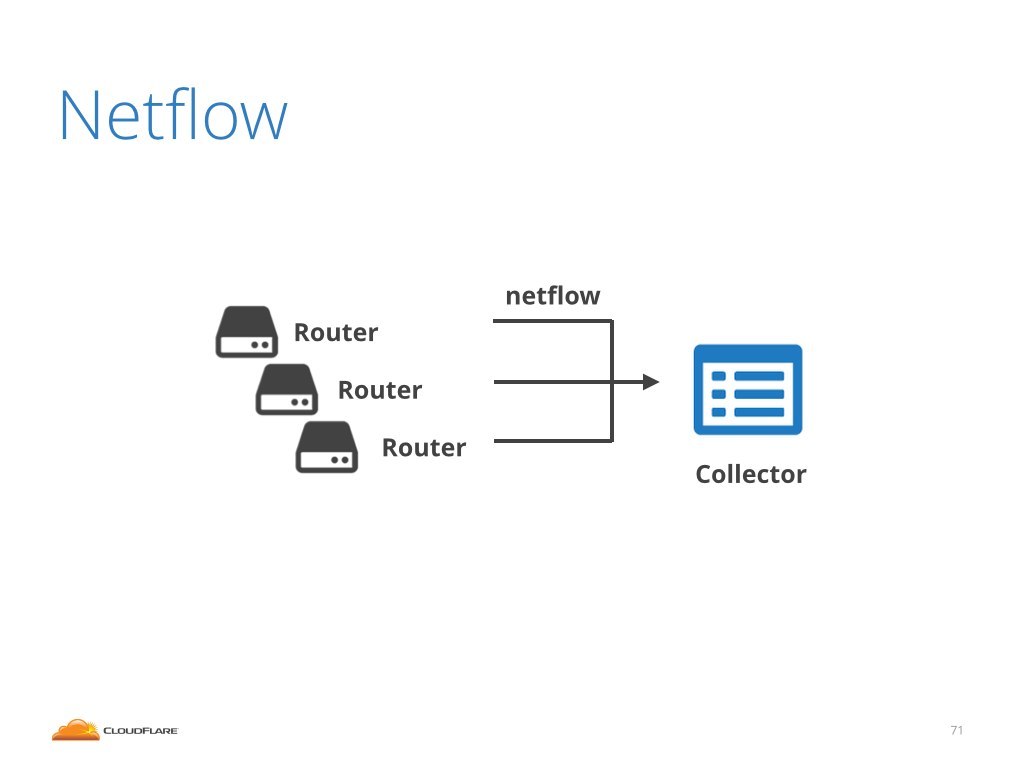
It allows routers to sample the traffic and send sampled data to a central place, called "collector". With properly configured netflow a router will report every thousandth, or ten thousandth connection to the collector.
This data contains the router interface numbers, which is precisely what we need. This would allow us to answer the question: over which interface the attack entered the carrier network.

Netflow is well supported by open source tools. Installing the collector is as simple as "apt-get install". Netflow scales up well, it can support truly big networks.
Proposing more logging may sound icky from the privacy point of view. This is a valid concern, but there are three caveats.
First, netflow allows to customize a sampling rate. I could be set to the maximum value of only one per 64000 connections tracked. This sampling rate is absolutely sufficient for the large DDoS reporting. The big attacks will be still clearly visible.
Secondly, netflow doesn't look into packet contents. Netflow enabled routers report only the basic metadata of sampled connections, stats like: IP addresses, interface numbers and bandwidth counters. These numbers aren't very exciting in raw format, without aggregating.
Lastly, there is no need to keep old logs available. For the DDoS reporting, the logs could be rolled every coupe of days. We really care only about recent events.

To convince you it's simple, here's an example of an nfdump command
used to query the collector. Here we ask a question: what attacks were
seen in last 5 minutes coming over a specific interface in Warsaw.
You can do much more with nfdump. This is just an example.
There are also much prettier backends to the netflow database. Using command line is just one way of querying it.

Asking internet carriers to deploy netflow is only the first step. It won't solve the attacks.

But being able to attribute the attacks will at least allow us to finally have an informed discussion. We can't have it now. We are in total darkness. Who is behind the attacks? Is that rogue ISP? Is that a script kiddie with access to couple of beefy hacked servers? Is that a state actor? We just don't know.

That's all I have. Thanks for being with me! I hope the talk was informative.
A quick recap. I believe that the threat of DDoS attacks is one of the forces causing centralization in the internet. In order to fix this we need to fix DDoS. In order to fix the big DDoS attacks we need to be able to trace them back and pinpoint who is behind them.

Hopefully, once we solve the attribution we'll be able to step by step tackle the DDoS and the internet will be better for everyone.
-
This is outdated! Now Cloudflare has 100 points of presence. ↩
-
Editor note: this presentation was prepared before the Krebs On Security DDoS attacks which had a different profile and did not use Spoofed IP addresses. Krebs's DDoS attacks launched by internet-of-things devices were unusually large. Most of the non-spoofed attacks were way smaller. This does not invalidate this talk. Non-spoofed attacks are easier to block - since the source addresses are known. It is also possible to fight and eventually destroy the botnets. This is much harder when the IP's are spoofed. ↩