IR is better than assembly
In the LLVM the compilation takes three stages (image from the AOSA book):
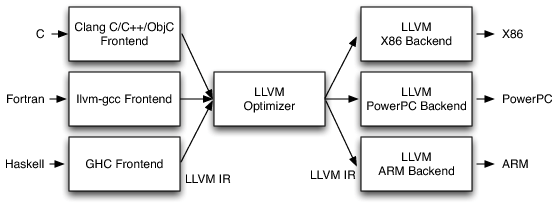
The stages are:
- The frontend, parsing original language and spiting out LLVM Intermediate Representation (IR) code1.
- The optimiser, mangling one IR into optimised equivalent IR. This stage does all the usual optimisations like constant propagation, dead code removal and so on.
- The backend, taking IR and producing machine code optimised for a specific CPU.
The crucial part is IR. It's a common language that sits between the high-level program and the low-level backend. IR is used to express high level concepts and is specific enough that any backend can produce a fast machine code.
IR is the heart of LLVM.
What is IR?
IR is a low-level programming language, pretty similar to assembly. From the AOSA book:
Unlike most RISC instruction sets, LLVM is strongly typed with a simple type system and some details of the machine are abstracted away. For example, the calling convention is abstracted through call and ret instructions and explicit arguments. Another significant difference from machine code is that the LLVM IR doesn't use a fixed set of named registers, it uses an infinite set of temporaries named with a % character.
IR code is usually generated by the frontend, but nothing stops us from writing it by hand. Let's do it!
Toolchain
You'll need clang and LLVM (llc, opt):
$ sudo aptitude install llvm clang
C to IR
The learning curve for IR, like for any assembly, is a bit steep. When starting with IR is it's easiest to compile a normal program, for example in C, to IR. That can be done using an LLVM frontend. Once we have IR we can tweak it and use an LLVM backend to produce a real machine code.
Consider the following C code:
unsigned square_int(unsigned a) { return a*a; }
Using clang we can generate IR. Flag -Os makes sure the produced
IR is shortest and should be easiest to read:
$ clang -Os -S -emit-llvm sample.c -o sample.ll
After removing some unnecessary boilerplate we get:
1 2 3 4 | define i32 @square_unsigned(i32 %a) { %1 = mul i32 %a, %a ret i32 %1 } |
IR is strongly typed and you can see types being repeated
everywhere. In line 1 we define a function that takes a single i32
parameter %a and returns type i32. In line 2 we assign the result
of multiplication to register %1 and we return it in the next line.
For more details please see the official documentation of the IR language.
Optimising
If you wish, you can run LLVM optimisations manually. The tool opt
can transform unoptimised IR to an optimised one. Our code is already
optimised, we used the -Os flag, but you can run opt anyway:
$ opt-3.0 -S sample.ll
IR to machine code
Finally, given IR we can use a backend to generate a machine code for a real CPU. Let's compile our IR:
$ llc-3.0 -O3 sample.ll -march=x86-64 -o sample-x86-64.s
This generates:
square_unsigned: imull %edi, %edi movl %edi, %eax ret
Fancy x86 32 bit assembler? Nothing simpler:
$ llc-3.0 -O3 sample.ll -march=x86 -o sample-x86.s
square_unsigned: movl 4(%esp), %eax imull %eax, %eax ret
How about ARM?
$ llc-3.0 -O3 sample.ll -march=arm -o sample-arm.s
square_unsigned: mov r1, r0 mul r0, r1, r1 mov pc, lr
Given IR it's trivial to compile it to a decent machine code for any architecture. Your hand crafted assembly code might be faster if you're lucky, but writing IR can have advantages:
- Your assembly code will not use faster instructions available in future CPU generations.
- Your code won't work on older CPU's.
- Porting assembly to another CPU architecture is tedious.
- You even need to spend time porting your assembler to different
operating systems. For example global symbols need underscores on
mac. Dealing with
#include's can be painful. - You need to be a serious expert to write assembly better than an LLVM compiler.
If you really can write better assembly than LLVM, please:
Don't write any more assembler by hand - write IR and create new LLVM optimisers instead.
It'll benefit everybody, not only you. Think about it - you won't need to write the same optimisations all over again on your next project!
Vectors in IR
The full power the IR language is visible when dealing with vectors. You can use any vector type you wish and not worry about the machine architecture underneath. For example, let's consider multiplying four 32 bit integers in parallel:
define <4 x i32> @multiply_four(<4 x i32> %a, <4 x i32> %b) { %1 = mul <4 x i32> %a, %b ret <4 x i32> %1 }
In my opinion this code looks much nicer than its C equivalent (using
vector extensions). The resulting assembly is long when LLVM compiles
it without option -march=avx,sse41, but with this option turned on
it becomes:
multiply_four: vpmulld %xmm1, %xmm0, %xmm0 ret
Similarly the result for ARM with -march=neon is decent:
multiply_four: mov r12, sp vmov d19, r2, r3 vldmia r12, {d16, d17} vmov d18, r0, r1 vmul.i32 q8, q9, q8 vmov r0, r1, d16 vmov r2, r3, d17 mov pc, lr
Finally
I think it's amazing that once written pseudo-assembly code can be retargetted to any architecture2. For me IR has all the advantages of assembly without any of its problems: fast, expressive, retargettable and maintainable.
If for some reason you're not happy with the machine code LLVM produces - write an LLVM optimiser (AOSA chapter 11.3.1).
-
Mayson Lancaster noted in a comment that LLVM IR is not the first intermediate language in the history of computing. For example this was discussed in Michael Franz's Phd thesis in '94. ↩
-
Many readers note this is not that simple. Frontend generated IR may differ depending on backend architecture. I still believe it's possible to write cross-platform IR. ↩
Comments
From: Vitaly Vidmirov > "Similarly the result for ARM with -march=neon is decent:" Are you joking? Right? ARM code in your examples is ridiculous. It is sad, that LLVM can't eliminate useless movs even in such trivial examples. square_unsigned: mul r0,r0,r0 mov pc,lr Your examples use soft-float-abi then floating point data transfered in integer registers. For compatibility with FPU-less processors. ARM processors before Cortex A15 has decoupled FPU, so fp<->int transfers cause huge stalls to serialize pipelines. multiply_four: vmul.i32 q0, q0, q1 mov pc,lr
From: giampaolo eusebi To the attention of Vitaly: From the ARM information center Assembler reference: For the MUL and MLA instructions, Rn must be different from Rd in architectures before ARMv6.
or leave a comment here.