Concurrent queue in C
I needed a queue implementation written in C for one of my ever-experimental projects. The complex part was to make it thread-safe - it was going to be used for exchanging data between threads.

Usually, I'd just take the doubly linked list implementation from the linux kernel1, wrap it in a mutex and quickly move on to another challenge.
This time though, I decided to make sure the queue is as efficient as possible. The mutex solution has at least few deficiencies:
- A queue is a much simpler data structure than way than a list. It
has also smaller memory footprint - a FIFO queue requires a single
pointer per element (
next), while doubly linked list requires two (prevandnext). - Mutexes are relatively heavy.
There is a better way. My CPU has
CMPXCHG instruction
for a reason - to enable lock-free algorithms. Additionally
GCC exposes it as an easy-to use extension
- __sync_bool_compare_and_swap.
I decided to try to write a lock-free queue using CAS.
Lock-free queue
Actually, writing lock-free algorithms is pretty hard. One has to know a hell lot about the internals of a CPU and memory ordering. Urlich Drepper's "What every programmer should know about memory" provides some background for that.
Although I'm usually suffering a constructive "Not Invented Here" syndrome, I decided to consult the literature and quickly found exactly what I was looking for: a paper by Maged Michael and Michael Scott "Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms".
The paper describes a concurrent non-blocking Queue using two CAS instructions per enqueue/dequeue operations. My implementation followed closely the design from the paper, but unfortunately it didn't work.
The main reason was an in-practical approach to memory allocation. In the paper authors write:
If the tail pointer lags behind and a process frees a dequeued node, the linked list can be broken [...] Valois therefore proposes a special mechanism to free and allocate memory.
Well, that's cryptic. The devil is in this code:
tail = root->tail; next = tail->next;
At this point tail may as well be freed and tail->next may point
to invalid memory address by the time we execute it. This is pretty
much the biggest problem here: pointers don't play nicely with CAS
(unless you have a very special memory allocator and deal with memory
allocation explicitly in the queue code).
Blocking queue
Fortunately the paper proposes also a blocking queue implementation with locks. Fortunately it's quite trivial. My implementation follows.
Prelude
struct queue_head { struct queue_head *next; }; struct queue_root { struct queue_head *head; struct queue_head *tail; struct queue_head divider; [... locks ...] };
Enqueue
void queue_put(struct queue_head *new, struct queue_root *root) { new->next = NULL; _lock(&root->tail_lock); root->tail->next = new; root->tail = new; _unlock(&root->tail_lock); }
Dequeue
The divider element will always be put on the queue. That allows us
to assume that the queue will always have at least a single item
enqueued, and therefore simplify implementation - no need to check if
head or tail are NULL.
struct queue_head *queue_get(struct queue_root *root) { struct queue_head *head, *next; while (1) { _lock(&root->head_lock); head = root->head; next = head->next; if (next == NULL) { // Only a single item enqueued: // queue is empty _unlock(&root->head_lock); return NULL; } root->head = next; _unlock(&root->head_lock); if (head == &root->divider) { // Special marker - put it back. queue_put(head, root); continue; } head->next = QUEUE_POISON1; return head; } }
The algorithm is trivial and depends mostly on the performance of the locks.
Semi-blocking queue
Now that we've explored the complexities of the non-blocking and blocking queue implementations we can dive into something more subtle - a mixed approach.
You see, CAS is a great instruction, but as mentioned above, it's
quite hard to use correctly when dequeueing due to the risk of
dereferencing already-freed pointer.
But CAS works perfectly when adding items to a structure that
doesn't require dereferencing anything. Like a simple stack.
Let's try to implement a mixed-approach queue:
- For enqueueing we'll add items to a stack using a simple
CASstatement. - When dequeueing, we'll have a separate stack and we'll wrap it in a standard lock.
- When the dequeueing stack is empty we'll reverse the order of enqueue stack and move the items to the dequeue one.
Advantages of this approach:
- Enqueueing is simple and has a constant time - single
CASinstruction should usually do. - Dequeueing is more complex, requires a lock and reversing the order
of the stack (cost
O(n)).
Here's the enqueue code:
void queue_put(struct queue_head *new, struct queue_root *root) { while (1) { struct queue_head *in_queue = root->in_queue; new->next = in_queue; if (_cas(&root->in_queue, in_queue, new)) { break; } } }
Dequeue is more complex, let's start with the situation where dequeue queue is not empty - we just need to pop an item from it:
struct queue_head *queue_get(struct queue_root *root) { _lock(&root->lock); if (!root->out_queue) { [...] } struct queue_head *head = root->out_queue; if (head) { root->out_queue = head->next; } _unlock(&root->lock); return head; }
And the code to move items from one enqueue to dequeue:
if (!root->out_queue) { while (1) { struct queue_head *head = root->in_queue; if (!head) { break; } if (_cas(&root->in_queue, head, NULL)) { // Reverse the order while (head) { struct queue_head *next = head->next; head->next = root->out_queue; root->out_queue = tail; head = next; } break; } } }
Benchmark
Benchmarking is hard and this time is not an exception. Additionally, we're benchmarking two algorithms with quite different characteristics.
The benchmark is rather simplistic and works as follows:
- First, we create a queue with a given number of elements enqueued.
- Next, we spawn a number of worker
threads. - Every thread repeats in a loop:
- Enqueue a single element.
- Dequeue a single element.
- Every thread periodically (around 10HZ) reports the speed of the loop.
- The main program sums up the reports and prints them on the screen every second (1HZ). The number represents a total count of loop passes per second, which is equal to number of enqueued and dequeued elements.
Four threads (on four cores):
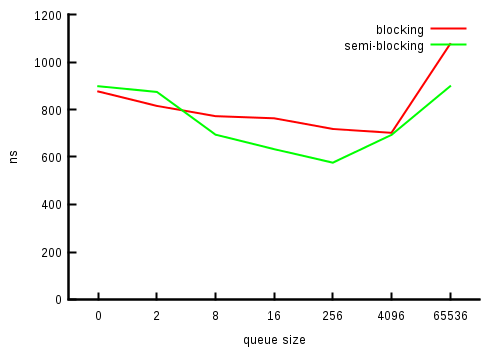
Single thread:
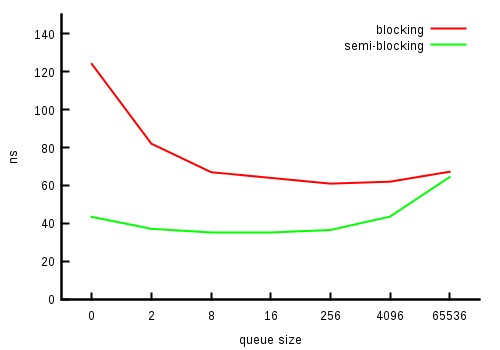
Summary
The results are pretty much as expected. For single-threaded case
semi-blocking queue was about three times faster than the blocking
implementation. Considering the fact that blocking one has to deal
with the divider placeholder pretty often, it's
understandable. Later, when the queue size grows the speed difference
is around 2x, until the queue grows very large when the cost of memory
misses starts to dominate.
Remember, that the benchmark is pretty specific. Not often you do enqueue and dequeue in a row, and not often you have four cores competing for the queue.
In the end, I think we haven't learnt much. I'll most likely stick to the blocking Queue implementation with spinlocks (spinlocks are faster than mutexes in uncontended scenario).
The semi-blocking Queue has potential but I don't like the cost of gets being proportional to the queue length in pessimistic case.
-
In fact, kernel's list implementation is a circular list. ↩